-
youtube text mining 1ML, DL & Python/Youtube 크롤링 & 분석 2019. 5. 6. 19:02
안녕하세요.
저번 유튜브 댓글 크롤링에 이은 댓글을 이용한 text mining을 해보도록 하겠습니다.
먼저 저번에 긁어왔던 댓글 데이터를 불러와보도록 하겠습니다.

유튜브 댓글 데이터 현재 보시는 것 처럼 댓글 데이터는 불필요한 이모티콘, ㅋㅋ, ㅎㅎ 같은 문자들이 존재 합니다. 텍스트 마이닝에서 중요한 것은 이러한 불필요한 단어들을 없애주는 전처리가 굉장히 중요합니다. 따라서 이러한 이모티콘들을 없앤 뒤 분석을 하겠습니다.
먼저 re 모듈을 import 받아서 불용어구들을 compile해주겠습니다.
#이모티콘 제거 emoji_pattern = re.compile("[" u"\U0001F600-\U0001F64F" # emoticons u"\U0001F300-\U0001F5FF" # symbols & pictographs u"\U0001F680-\U0001F6FF" # transport & map symbols u"\U0001F1E0-\U0001F1FF" # flags (iOS) "]+", flags=re.UNICODE) #분석에 어긋나는 불용어구 제외 (특수문자, 의성어) han = re.compile(r'[ㄱ-ㅎㅏ-ㅣ!?~,".\n\r#\ufeff\u200d]')그 다음으로는 기존의 데이터에서 댓글컬럼만 뽑아냅니다
comment_list = [] for i in range(len(comment_data)): comment_list.append(comment_data['comment'].iloc[i])최종적으로 compile한 문자열을 이용하여 불용어구를 제외하고 댓글을 보기 쉽게 데이터 프레임으로 저장합니다.
comment_result = [] for i in comment_list: tokens = re.sub(emoji_pattern,"",i) tokens = re.sub(han,"",tokens) comment_result.append(tokens) comment_result = pd.DataFrame(comment_result, columns=["comment"])
텍스트 전처리 전/후 보시다시피 텍스트가 훨씬 간결해지고 보기 좋게 변한 것을 알 수 있습니다.
하지만 중간중간에 하트/별모양 이런 특수문자들이 간혹 보이기는 하지만 유니코드를 좀 더 공부해야 원인을 알 수 있을 것 같습니다!
그렇다면 전처리만 했다고 끝인가? 이제부터 본격적으로 text mining를 해보도록 하겠습니다. 텍스트 전처리는 모델링이나 시각화를 하기전에 이상치를 제거하고 선형성, 상관성을 확인하고 제거하거나 수정하는 연속형 데이터 전처리처럼 분석을 위해서 최적의 데이터 상태로 만들어 놓은 것입니다.
다음으로 형태소 분석을 실시하겠습니다. 한국어 정보처리 패키지인 konlpy를 사용했습니다.
konlpy에는 twitter, komoran, kkma, mecab의 모듈이 존재하는데 이중에서 mecab는 window에 빌드를 하려면 시간과 노력이 들기 때문에 추후 포스팅에서 다시 한번 다뤄보겠습니다. 지금은 가장 적은 시간이 걸리고 분류시에 고유명사, 일반명사 등을 모두 포함하고 있는 twitter을 이용하여 분류해보도록 하겟습니다.
konlpy에 대한 자세한 설명은 아래의 사이트에서 참고하셔도 될 것 같습니다.
KoNLPy: 파이썬 한국어 NLP — KoNLPy 0.4.3 documentation
KoNLPy: 파이썬 한국어 NLP KoNLPy(“코엔엘파이”라고 읽습니다)는 한국어 정보처리를 위한 파이썬 패키지입니다. 설치법은 이 곳을 참고해주세요. NLP를 처음 시작하시는 분들은 시작하기 에서 가볍게 기본 지식을 습득할 수 있으며, KoNLPy의 사용법 가이드는 사용하기, 각 모듈의 상세사항은 API 문서에서 보실 수 있습니다. >>> from konlpy.tag import Kkma >>> from konlpy.utils import pprin
konlpy.org
저는 추후에 w2v를 사용하여 단어간의 연관성 및 군집분석, pca를 진행하고자 일단 명사만을 분류해보겠습니다.
from konlpy.tag import Twitter def get_noun(comment_txt): twitter = Twitter() noun = [] if len(comment_txt)>0: tw = twitter.pos(comment_txt) for i,j in tw: if j == 'Noun': noun.append(i) return noun comment_result['token'] = comment_result['comment'].apply(lambda x: get_noun(x))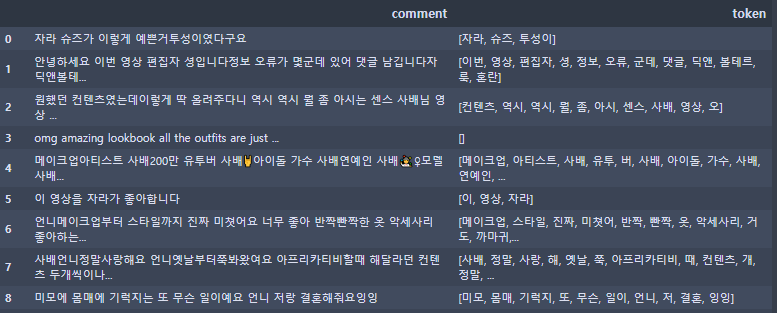
댓글 tokenizing 분류한 단어들을 보시면 분류기가 어느정도 정확하게 명사를 분류해준 것을 알 수 있습니다. 이 외에 필요한 단어들은 사전에서 추가하시면 됩니다.
이렇게 문장에서 단어들을 추출하는 과정을 tokenizing라고 하는데 Text mining에서는 분석을 위해서 중요한 과정이라고 볼 수 있습니다. 물론 이렇게 단어를 정확하게 분류하기 위해서는 말씀드렸다시피 깔끔한 텍스트 전처리가 필요하겠죠?
다음은 데이터 분석에서 인사이트 도출이나 feature engineering 설계를 위해서 중요한 시각화를 해보고자 합니다.
두개의 시각화를 해보았는데요 하나는 bar plot이며 다른 하나는 wordcloud입니다. 한번 보시고 어떠한 시각화가 나은지 확인해보시기 바랍니다.
from collections import Counter from wordcloud import WordCloud #import matplotlib as mpl import matplotlib.pylab as plt import numpy as np noun_list = [] for i in range(len(comment_result)): for j in range(len(comment_result['token'].iloc[i])): noun_list.append(comment_result['token'].iloc[i][j]) counts = Counter(noun_list) tags = counts.most_common(30) #bar chart test = pd.DataFrame({'word':[], 'count':[]}) for i in range(len(tags)): word = tags[i][0] count = tags[i][1] insert_data = pd.DataFrame({'word':[word], 'count':[count]}) test = test.append(insert_data) test.index = range(len(test)) index = np.arange(len(test)) plt.bar(index,test['count'].tolist() ) plt.xlabel('word', fontsize=5) plt.ylabel('count', fontsize=5) plt.xticks(index, test['word'].tolist(), fontsize=5, rotation=30) plt.title('단어 빈도수 시각화') plt.show() #wordcloud wc = WordCloud(font_path='/Users/tlsal/Downloads/탬플릿/NanumSquareL.ttf',background_color='white', width=800, height=600) print(dict(tags)) cloud = wc.generate_from_frequencies(dict(tags)) plt.figure(figsize=(10, 8)) plt.axis('off') plt.imshow(cloud) plt.show()
1) barplot 2)wordcloud 제가 생각했을 때는 barplot보다 wordcloud가 눈에 띄고 훨씬 잘 와닿는 것 같습니다. 수치형, 연속형 데이터에 대해서 시각화 할 때는 barplot이나 pieplot등의 그래프가 좋지만 보는 사람으로 하여금 한눈에 들어오고 인사이트 도출 측면에서 text데이터에 대해서는 wordcloud가 좋은 시각화라고 생각합니다.
시각화 결과를 함께 살펴보면 "언니", "모델", "메이크업", "패션", "옷", "화장", "영상" 등의 단어로 미루어봤을 때 단어만 보더라도 "여성 패션/뷰티 유튜버"인것을 이레 짐작할 수 있습니다.
이처럼 시각화를 통해서만 해당 단어들이 어떠한 것을 나타내고 있는지를 알 수 있는 것이 시각화를 하는 중요한 이유라고 생각하고 또한, 텍스트 데이터를 시각화만 했을 뿐인데 어떠한 부류에 속하는지 알수 있는 것이 텍스트 데이터의 묘미라고 생각이 듭니다.
다음 포스팅에서는 w2v와 cluster을 통해서 어떠한 단어들간의 연관이 있는지 또, 어떠한 단어들끼리 군집이 형성되어 군집별로 어떠한 성향을 지니는지 분석하고 시각화까지 하는 그런 시간을 갖도록 하겠습니다!
긴 글 읽어주셔서 감사합니다.
'ML, DL & Python > Youtube 크롤링 & 분석' 카테고리의 다른 글
유튜버 분석 (14) 2019.05.25 youtube text mining3 (0) 2019.05.11 youtube text mining 2 (0) 2019.05.08 유튜브 댓글 크롤링 (11) 2019.05.05 유튜브 크롤링 (56) 2019.05.04