-
유튜브 크롤링ML, DL & Python/Youtube 크롤링 & 분석 2019. 5. 4. 16:56
안녕하세요. 업무를 하다가 문득 떠오른 아이디어가 있어서 유튜브 크롤링을 하게 되었습니다.
유튜버들은 유튜브만의 분석 솔루션이 따로 있다고 알고 있는데 "과연, 그것이 얼마나 도움을 줄 수 있을까?" 라는 생각과 "직접 데이터를 수집하여 분석하고 인사이트를 도출해줄 수 있지 않을까?"라는 생각을 하게 되었습니다.
따라서 주제는 유튜버들중 한분을 정해서 데이터 수집부터 분석까지 진행해보고자 합니다.
또한, 본 포스팅에서는 유튜버에 대한 크롤링을 해보고자 합니다.
저는 "이사배"라는 유튜버분을 크롤링했습니다.
저는 Selenium으로 크롤링을 진행했습니다. 크롤링을 하는 여러 방법중에 가장 직관적이지만 시간이 오래걸리고 복잡하고 오류가 많다는 단점이있죠.
1. 먼저 크롤링에 필요한 모듈을 import합니다
import requests from bs4 import BeautifulSoup import time import urllib.request # from selenium.webdriver import Chrome import re from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys import datetime as dt2. url을 불러오기 위한 사전 작업을 실행합니다.
selenium은 간단히 말해서 컴퓨터 = 나 라는 생각을 하시면 됩니다.
delay=3 browser = Chrome() browser.implicitly_wait(delay)2-1 우리의 대상은 유튜버기 때문에 유튜브 url로 접속합니다.
start_url = 'http://www.youtube.com' browser.get(start_url) browser.maximize_window()3. 유튜브에 접속했으면 개발자도구를 켭니다(F12) 그러면 여러분들이 보고 있는 창의 page source들이 보일 겁니다.
개발자도구 저기 보이는 화살표를 클릭하거나 Ctrl+shift+c를 눌러줍니다.
우리가 필요한 것은 "이사배" 라는 유튜버를 검색해야 하므로 page source에서 검색창을 찾아줍니다.
검색창 page source화면 4. 이제 검색창 영역을 클릭한 뒤 검색하고 싶은 유튜버를 입력한 뒤 enter클릭합니다.
selenium이나 beautifulsoup를 이용하여 html 코드를 찾는 방법으로는 css / xpath / xml 등의 방법이 있습니다. 저는 여기서 xpath를 이용하여 원하는 html태그와 속성을 찾아보겠습니다.(공간활용과 더 자세하게 방법을 다루기 위해서 xpath, css selector방법은 따로 포스팅하겠습니다.)
browser.find_elements_by_xpath('//*[@id="search-form"]/div/div/div/div[2]/input')[0].click() #검색창영역클릭 browser.find_elements_by_xpath('//*[@id="search-form"]/div/div/div/div[2]/input')[0].send_keys('이사배')#검색창 영역에 원하는 youtuber입력 browser.find_elements_by_xpath('//*[@id="search-form"]/div/div/div/div[2]/input')[0].send_keys(Keys.RETURN)#엔터4-1. 이동한 화면에서 유튜버 "이사배"를 클릭합니다.
browser.find_elements_by_xpath('//*[@class="yt-simple-endpoint style-scope ytd-channel-renderer"]/div[2]/h3/span')[0].click()이제 제가 추출하고 싶은 정보는 "이사배"님의 영상정보와 댓글입니다. 따라서 먼저 영상별로 정보를 수집해보겠습니다.
5. 유튜버에 들어간 뒤 카테고리가 보이는데 여기서 동영상 카테고리를 클릭합니다.

유튜버의 동영상 카테고리 클릭 browser.find_element_by_xpath('//*[@class="scrollable style-scope paper-tabs"]/paper-tab[2]').click()5-1. 유튜브는 스크롤을 내리지 않으면 모든 영상들이 page source에 보이지 않기 때문에 스크롤을 내리는 작업을 선행해줍니다.(시간상 스크롤 끝까지 내리지 않고 20회정도로 한정하여 스크롤해보겠습니다.)
body = browser.find_element_by_tag_name('body')#스크롤하기 위해 소스 추출 num_of_pagedowns = 20 #10번 밑으로 내리는 것 while num_of_pagedowns: body.send_keys(Keys.PAGE_DOWN) time.sleep(2) num_of_pagedowns -= 15-2. 위의 과정을 거치면 거의 모든 영상정보에 대해서 source가 보이는 것을 확인할 수 있습니다. 그러면 이제 내가 원하는 정보를 수집해봅시다!
저는 영상정보에서 영상이름/썸네일/조회수 등의 영상에서 필요한 대부분의 정보를 수집했습니다.
여기서 중요한 것은 selenium은 굉장히 오래걸리기 때문에 selenium으로 필요한 부분까지만 진행하고 나머지는 beautiful soup, request로 작업하는 것이 시간과 노력이 굉장히 절감됩니다.
내가 작업하고 있는 환경의 page source를 추출하는 코드는 매우 쉽습니다.
html0 = browser.page_source html = BeautifulSoup(html0,'html.parser')해당 과정을 거치면 beautiful soup를 이용하여 크롤링을 진행할 수 있습니다.
6. 추출한 결과를 보여드리겠습니다 추출하기 위한 코드는 길기때문에 모든 정보를 담을 수 없어 github에 올려놓도록 하겠습니다.
https://github.com/minyong-shin/Bloging/tree/master/
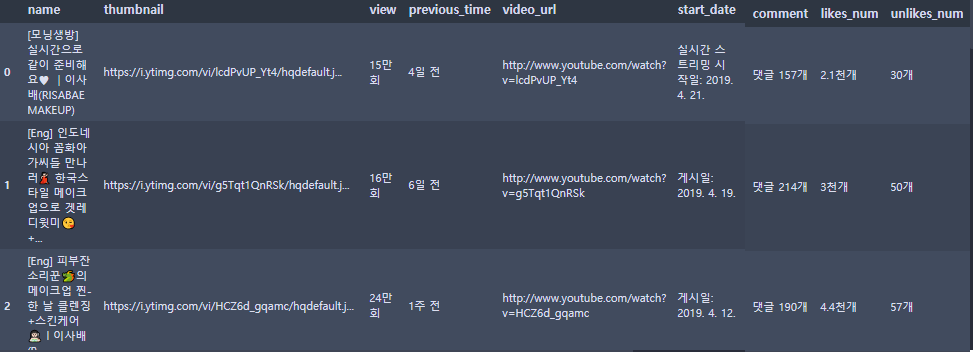
영상정보에서 추출한 데이터 여기까지 유튜버들의 영상정보를 크롤링 하는 방법을 알아봤는데요, 해당 데이터로 제가 해보려고 하는 것은 "시각화"를 해보려고 합니다. 유튜버 "이사배"님의 영상제목을 tokenize하여 명사와 형용사를 추출하여 제목에 어떤 명사, 형용사가 들어갔을 때 조회수, 댓글, 좋아요 수가 많은지를 시각화해보려고 합니다.
과연 어떤 단어가 들어갔을 때 조회수, 댓글, 좋아요 수가 많은지 다음 포스팅에서 뵙겠습니다.
'ML, DL & Python > Youtube 크롤링 & 분석' 카테고리의 다른 글
유튜버 분석 (14) 2019.05.25 youtube text mining3 (0) 2019.05.11 youtube text mining 2 (0) 2019.05.08 youtube text mining 1 (4) 2019.05.06 유튜브 댓글 크롤링 (11) 2019.05.05