-
유튜버 분석ML, DL & Python/Youtube 크롤링 & 분석 2019. 5. 25. 17:10
이번 포스팅은 문득 생각난 의문에서부터 시작한 분석입니다.
"유튜버들은 왜 자극적인 제목으로만 사람들의 관심을 끄는 것인가?"
그래서 유튜버들에게 맞춤 키워드를 추천해줄 수 있으면 어떨까 라는 생각을 하게 되었습니다.
따라서 본 포스팅에서는 한 유튜버 "테스터 훈"을 선택해 영상정보들을 수집하여 분석을 시작해보도록 하겠습니다.
1. 테스터훈 영상정보를 수집하겠습니다.
제가 필요한 정보는 영상에 직접 들어가서 수집해야하는 데이터이기 때문에 먼저 각 영상별 url을 수집하도록 하겠습니다.

각 영상 리스트 html0 = browser.page_source html = BeautifulSoup(html0,'html.parser') video_ls=html.find_all('ytd-grid-video-renderer',{'class':'style-scope ytd-grid-renderer'}) b = html.find('div',{'id':'items','class':'style-scope ytd-grid-renderer'}) len(b.find_all('ytd-grid-video-renderer',{'class':'style-scope ytd-grid-renderer'}))#450개의 영상정보를 수집 tester_url = [] for i in range(len(video_ls)): url = start_url+video_ls[i].find('a',{'id':'thumbnail'})['href'] tester_url.append(url)2. 수집한 영상의 url을 통해 Selenium을 이용하여 영상정보 크롤링
제가 수집할 데이터는 영상제목/영상조회수/댓글수/좋아요/싫어요를 수집하려고 합니다.
영상마다 들어가서 각 영상별 데이터를 수집해오는 것입니다.
soup0 = browser.page_source soup = BeautifulSoup(soup0,'html.parser') info1 = soup.find('div',{'id':'info-contents'}) #댓글을 막아놓은 영상이 있기 때문에 예외처리를 꼭해준다. try: comment = soup.find('yt-formatted-string',{'class':'count-text style-scope ytd-comments-header-renderer'}).text except: comment = '댓글x' title = info1.find('h1',{'class':'title style-scope ytd-video-primary-info-renderer'}).text #영상제목 view =info1.find('yt-view-count-renderer',{'class':'style-scope ytd-video-primary-info-renderer'}).find_all('span')[0].text #영상 조회수 like = info1.find('div',{'id':'top-level-buttons'}).find_all('yt-formatted-string')[0].text #좋아요수 unlike = info1.find('div',{'id':'top-level-buttons'}).find_all('yt-formatted-string')[1].text #싫어요수 date = soup.find('span',{'class':'date style-scope ytd-video-secondary-info-renderer'}).text#영상업로드날짜이렇게하여 수집한 데이터는 다음과 같습니다.
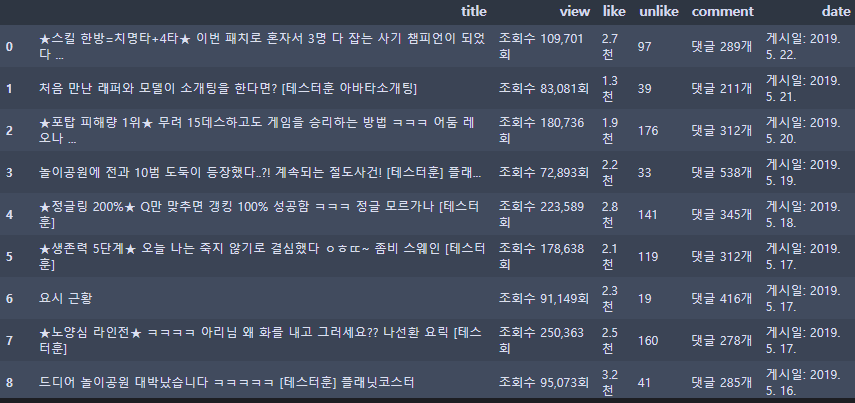
자 이제 데이터 수집을 완료했으니 본격적으로 분석에 들어가보도록 하겠습니다.
2-2 좋아요수 / 댓글수 / 조회수의 상관관계
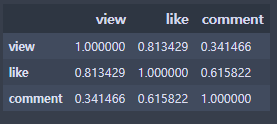
상관계수 
상관관계 히트맵 좋아요 수와 댓글수/조회수는 높은 상관관계를 보인다. 댓글수와 조회수는 0.34의 상관관계를 보이지만 이정도면 준수한 편인 것을 알 수 있다.
3. 데이터 분석전 고민
저는 분석에 앞서 고민에 빠졌습니다. 맞춤 키워드를 위해서는 텍스트별로 어느정도의 영향력(조회수 / 댓글수 / 좋아요수)을 가지고 있는지 판단하기 위해서는 표준화 과정이 필요했습니다. 변수별로는 표준정규분포식으로 변환하여 스케일을 진행하거나 min-max scale를 진행하는 등의 표준화 방법들이 다양했지만, 각 변수에서 날짜별로 표준화가 필요했습니다.
즉, 날짜에 따라서 게시한지 오래된 영상은 당연히 조회수가 높기 마련이기 때문에 그것을 해결해야하는 이슈를 지니고 있었습니다. 그래서 제가 생각한 방식은 두가지인데요, 날짜별로 가중치를 부여해서 표준화를 하는 것입니다.

일단 위와 같은 방법은 저도 프로토타입처럼 가지고 있는 생각인거지 좀 더 통계적으로 고민을 한 뒤에 이와 관련해서는 자세하게 수정하거나 포스팅을 하도록 하겠습니다.
따라서 지금은 날짜 이런 것들은 고려하지 않고 그대로 진행하겠습니다.
4. Text Cleansing
먼저 텍스트에서 인터넷 유니코드같은 범용문자들을 제거해야했습니다.
#이모티콘 제거 emoji_pattern = re.compile("[" u"\U0001F600-\U0001F64F" # emoticons u"\U0001F300-\U0001F5FF" # symbols & pictographs u"\U0001F680-\U0001F6FF" # transport & map symbols u"\U0001F1E0-\U0001F1FF" # flags (iOS) "]+", flags=re.UNICODE) #분석에 어긋나는 불용어구 제외 (특수문자, 의성어) han = re.compile(r'[ㄱ-ㅎㅏ-ㅣ!?~,".\n\r#\ufeff\u200d]') title_ls=[] for i in range(len(ttt)): a = re.sub(emoji_pattern,'',ttt['title'].iloc[i]) b = re.sub(han,'',a) title_ls.append(b) ttt['title']=title_ls5. tokenize
그 다음으로 영상제목을 토큰화하는 과정입니다.
#영상제목 토큰화 하는 과정 noun_final = [] for text in range(len(ttt)): noun0=kkma.pos(ttt['title'].iloc[text]) noun=[] for i,j in noun0: if j=='NNG': if i == '테스터' or i == '훈': pass else: noun.append(i) noun_final.append(noun) ttt['token'] = noun_final #토큰화 작업을 거친 뒤에 단어가 하나인 것은 제외하기 noun_ls = [] for i in range(len(ttt)): noun_ls0=[] for j in range(len(ttt['token'].iloc[i])): if len(ttt['token'].iloc[i][j]) == 1: pass else: noun_ls0.append(ttt['token'].iloc[i][j]) noun_ls.append(list(set(noun_ls0))) #중복제거결과는 다음과 같습니다

6. 각 키워드를 기준으로 조회수 정렬하기
token_df = pd.DataFrame({'token':[]}) for i in range(len(ttt)): insert_data = pd.DataFrame({'token':ttt['token2'].iloc[i]}) insert_data['view'] = ttt['view'].iloc[i] token_df = token_df.append(insert_data) token_df2 = token_df.groupby('token')['view'].sum().reset_index() #키워드별 조회수 합 token_df2['count'] = token_df.groupby(['token']).count().reset_index()['view'].tolist() #각 키워드의 갯수 #키워드별 조회수의합 / 갯수 - 동등하게 만들어야 하기 때문에 view_count = [] for i in range(len(token_df2)): a = token_df2['view'].iloc[i]/token_df2['count'].iloc[i] view_count.append(a) token_df2['view_count'] = view_count
단순 키워드 빈도수 
키워드별 조회수 High TOP15 
키워드별 조회수 Low TOP 15 7. 최종정리
댓글과 좋아요수 조회수는 어느정도 높은 상관관계를 지니고 있으며 거의 비슷한 결과가 나오는 것을 확인했다. (다른 두개의 변수도 직접 해보시면 좋을 것 같아요.)
해당 유튜버의 키워드별 조회수를 정리해보겠습니다.
단순 키워드 빈도만 놓고 보자면 "게임 유튜버"답게 게임 용어와 관련된 텍스트가 굉장히 많이 나타나는 것을 알 수 있습니다. 하지만 게임관련 단어의 빈도수가 높기 때문에 조회수나 댓글수가 높게 측정되는 것이지 해당 단어가 나온다고 해서 무조건적으로 조회수나 댓글이 높다고 판단을 하면 안됐습니다. 그래서 순수하게 해당 단어가 나왔을 때 조회수가 어떻게 되는지 확인하기 위해서 단어의 조회수합을 단어별 빈도수로 나누기로 했습니다.
따라서 이에 대한 설명을 하겠습니다.
먼저 high top 15를 보겠습니다. 키워드만 놓고 봤을 때 게임관련 키워드는 비교적 하위 순위에 속하며 음식 관련 키워드들이 상위권을 차지하고 있는 것을 확인할 수 있습니다. 이를 통해 제가 알게된 것은 해당 유튜버는 "게임 유튜버"지만 음식관련 영상이 올라왔을 때 조회수가 높은 것으로 보아 구독자들은 이 유튜버가 음식을 먹을 때 더 재미있어 하며, 흥미를 느낀다는 것을 알 수 있었습니다.
다음은 Low top 15를 보겠습니다. 해당 단어들로 보아 커플관련 직업관련 즉, 게임이나 음식에 관련이 없는 영상이 올라오면 상대적으로 구독자들은 관심도가 떨어지는 것을 확인할 수 있었습니다.
이렇게 분석을 하다보니 그럼 이러한 키워드들은 어떻게 들어갔을 때 좋은 시너지를 낼 수 있는지에 대해서 궁금해지기시작했습니다. 따라서 해당 키워드를 이용해서 w2v와 kmeans클러스터를 통해서 단어간의 관계도 확인해보는 포스팅을 하도록 하겠습니다. 감사합니다.
'ML, DL & Python > Youtube 크롤링 & 분석' 카테고리의 다른 글
youtube text mining3 (0) 2019.05.11 youtube text mining 2 (0) 2019.05.08 youtube text mining 1 (4) 2019.05.06 유튜브 댓글 크롤링 (11) 2019.05.05 유튜브 크롤링 (56) 2019.05.04