-
youtube text mining 2ML, DL & Python/Youtube 크롤링 & 분석 2019. 5. 8. 17:12
text mining은 말 그대로 텍스트를 이용하여 데이터를 분석하는 것인데요, 연속형 자료 즉, 수치형 자료는 정형화된 자료로써 바로 분석에 사용되어도 무방한 데이터입니다. 하지만 텍스트 데이터는 비정형 자료로써 분석 하기에 앞서 수치형으로 바꿔주는 작업이 필요한데 이러한 작업을 w2v라고 합니다.
word2vec를 설명드리기 전에 초기의 단어들은 어떻게 분류 되었는지부터 설명드리겠습니다. 지금은 벡터 공간에 할당된 단어간의 유사도나 관련성을 기준으로 단어들을 분류하고 군집하는데요.
예전에는 "나이브 베이지안"을 통해서 특정 단어가 들어가면 "1", 특정 단어가 들어가지 않으면 "0"으로 두고 분류하는 작업을 시행했습니다. 하지만 이는 단어마다 어떠한 의미를 가지는지를 컴퓨터가 모르고, 단어의 의미는 쓰이는 곳에 따라서 다를 수 있기 때문에 한계점이 존재했습니다.
그래서 개발된 기술이 word2vec입니다. 단어를 벡터공간에 뿌려 단어의 의미를 벡터화할 수 있다면 그 의미는 명확해 질 것이라고 생각했습니다.
일단 단어들이 수치화가 되면 벡터 공간상의 거리를 통해서 유사도를 추출할 수 있을뿐더러 여러가지 통계적 방법들을 이용하여 통계적인 추론도 가능한 것입니다.
예를 들어서 장난감, 남자, 여자의 단어들이 있습니다. 해당 단어들을 벡터 공간에 할당한 뒤 연산을 해보겠습니다.
장난감 - 남자 + 여자 = ?? 어떤 것이 나올 것 같습니까?
신기하게도 위의 연산에 대한 답은 "인형"이었습니다. 이처럼 6-5=1만 연산할 수 있는 것이 아니라 단어도 숫자와 마찬가지로 연산이 가능하게 만드는 것이 word2vec입니다.
여러분들도 다음 사이트에서 여러 단어간의 연산을 해보시길 바랍니다
Korean Word2Vec
ABOUT 이곳은 단어의 효율적인 의미 추정 기법(Word2Vec 알고리즘)을 우리말에 적용해 본 실험 공간입니다. Word2Vec 알고리즘은 인공 신경망을 생성해 각각의 한국어 형태소를 1,000차원의 벡터 스페이스 상에 하나씩 매핑시킵니다. 그러면 비슷한 맥락을 갖는 단어들은 가까운 벡터를 지니게 되며, 벡터끼리 시맨틱 연산도 수행할 수 있습니다. 이는 분산 시맨틱스 가정에 기초하고 있습니다. CORPUS 실험을 위해 한국어 위키백과와 나무위키에서 제
word2vec.kr
그러면, 이제 word embedding부터 설명드리겠습니다
word embedding는 단어를 벡터공간에 할당하여 고차원의 데이터를 저차원의 데이터로 변환시켜서 데이터 간의 관계를 나타낼 수 있도록 하는 것입니다.
이는 컴퓨터가 인식하지 못하는 텍스트를 수치화 시켜서 컴퓨터가 인식할 수 있게끔 해주는 것입니다.
그럼 word embedding해서 단어를 벡터공간에 할당했다고 끝인가?
이제 벡터화된 단어를 이용해서 단어간의 유사도나 예측할 수 있는 모델이 필요할 것입니다.
이러한 모델을 word2vec이라고 하는데요
w2v은 두 종류로 나뉠 수 있습니다. 그것은 skip-gram 방식과 cbow방식입니다.
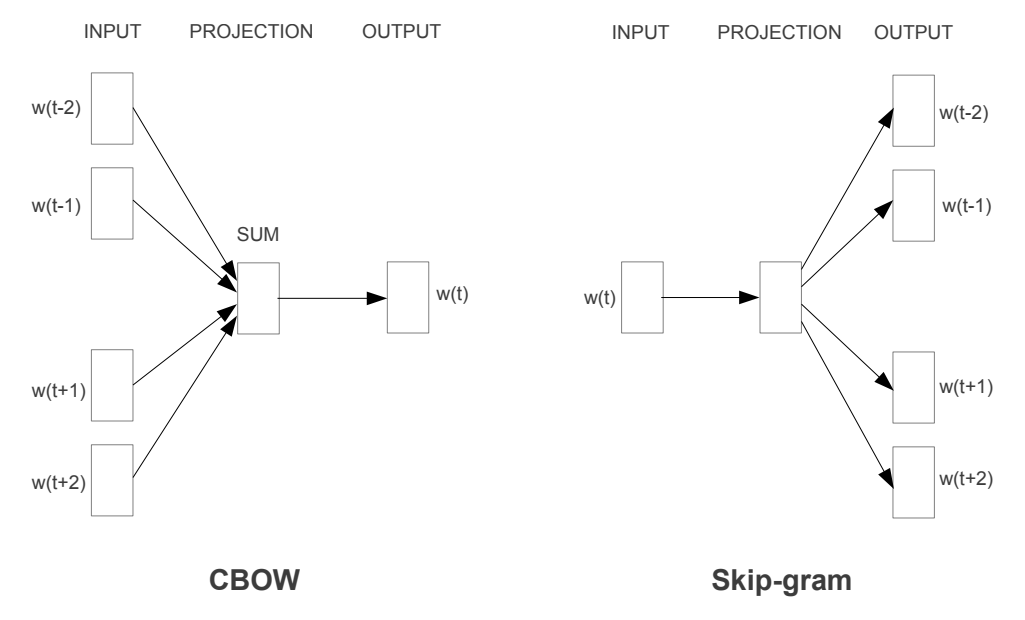
skip-gram / cbow 예시 위의 그림을 보시면 cbow는 뭔가 모이는 것 같고 skip-gram은 뭔가 퍼지는 것 같이 보이실겁니다. 좀 더 쉬운 예제를 보겠습니다.

이와 같이 CBOW방식은 중심 단어를 예측하는 것이고 Skip-gram방식은 중심이 되는 단어를 예측하는 것을 말합니다. 이해하기 쉬운 방법은 CBOW는 Center을 기억하시고 Skip-gram은 Side를 기억하는 것입니다.
주의할 것은 Cbow는 비교적 데이터의 수가 작은 것에서 실시하며 Skip-gram은 비교적 큰 데이터를 이용하는 것입니다.
이제 분석을 시작해보겠습니다.
이전 포스팅에서 Twitter을 이용해서 토큰화했엇죠? 그 데이터를 그대로 이용할 것입니다.
다음과 같은 데이터 형식을 준비하시면 되겠습니다.

그 다음으로 데이터를 보면 비어있는 리스트가 있습니다. 비어있는 리스트를 없애고 한음절로 되어 있는 단어도 없애겠습니다.
vec = [] for i in range(len(tm0)): vec2 = [] tm_ls = tm0['pc_text'].iloc[i] if len(tm_ls) == 0: #비어있는 리스트 삭제 pass else: for j in range(len(tm_ls)): #비어있지 않은 리스트 중에서 단어가 한 음절인 것은 pass if len(tm_ls[j]) > 1: vec2.append(tm_ls[j]) else: pass if len(vec2) == 0: pass else: vec.append(vec2)생성된 리스트는 다음과 같습니다.

자 이제 w2v를 하기 위한 준비는 끝났습니다. 이제 skip-gram으로 데이터를 word2vec으로 학습시키겠습니다.
model = Word2Vec(vec, min_count=3,window=3,iter=20, size=100, sg=1) #skip-gram저는 저번 wordcloud에서 가장 빈도수가 높았던 "언니"라는 단어로 유사도를 추출해보았습니다.
model.most_similar('언니')
"언니"와 유사도가 가장 높은 순은 "매력", "진짜", "모델" 등의 단어가 도출된 것을 알 수 있었습니다.
자세한 코드는 깃허브에 올려놨습니다.
https://github.com/minyong-shin/Bloging/tree/master/
'ML, DL & Python > Youtube 크롤링 & 분석' 카테고리의 다른 글
유튜버 분석 (14) 2019.05.25 youtube text mining3 (0) 2019.05.11 youtube text mining 1 (4) 2019.05.06 유튜브 댓글 크롤링 (11) 2019.05.05 유튜브 크롤링 (56) 2019.05.04