-
주식데이터 크롤링ML, DL & Python/주식데이터를 활용한 분석 2019. 5. 19. 22:17
이번 포스팅은 "네이버 금융"에 있는 주가데이터를 수집하여 분석해보는 시간을 가지려합니다
주식데이터를 크롤링하는 목적으로는 앞으로의 주가를 예측해보고 싶었기 때문입니다. 주가라는 것은 해당 기업의 사업모델, 사업 계획, 신제품 출시 등의 많은 영향을 받아서 많이 변동할 것입니다. 하지만 이와 같은 정보들은 정형적인 정보가 아닌 비정형 데이터로써 존재하고 있습니다.
그렇다면 비정형데이터가 아닌 수치화된, 연속형 데이터를 이용하여 주가를 예측해보면 어떨까 라는 생각을 했습니다. 이에 관해서 여러 정보들을 탐색해봤는데 앞서 말한 비정형 데이터를 이용하지 않고 연속화된, 수치화된 데이터를 이용하여 앞으로의 주가를 예측하고 탐색하여 수익을 얻는 방법이 "퀀트"라는 방법이 있었습니다.
퀀트는 간단히 말해서 value가치의 PER, PBR, PCR, quality가치의 roa, roe, 부채비율 등의 연속형 데이터를 이용하여 주가를 예측하고 그에 대한 백테스트를 진행하는 것을 말합니다. 여기서 중요한 것은 "저평가된 주식"에 있습니다. 저평가된 주식이란 기업의 당기순이익에 비해서 주가가 낮게 평가된 주식을 말하는데요, PER과 PBR이 낮은 주식들은 저평가된 주식이라고 볼 수 있습니다. 하지만 저평가된 주식이라고 모두 구입하는 것이 아니라 이유없이 저평가된 주식을 선별하는 것이 중요합니다.
이유없이 저평가된 주식은 기업 재무상 아무런 문제가 없고 금융위기가 찾아와도 기업의 재무구조와 수익에 아무런 영향을 받지 않았는데 투자가들이 이러한 사실들을 민감하게 받아들여 자기가 가지고 있는 주식을 팔아 해당 기업의 주가가 낮아진 것을 말합니다.
따라서 퀀트에서는 이렇게 이유없이 저평가된 주식을 골라내는 확률을 높이고 저평가된 주식을 구입하여 수익을 높이는데 목적이 있습니다. 그래서 앞으로의 포스팅에서는 PER, PBR, ROA, ROE등의 데이터들도 수집하여 퀀트투자가처럼 직접 기업의 데이터를 분석하여 해당 기업이 저평가된 기업인지 아닌지를 판별한 후 저평가된 기업들을 골라내는 작업까지 진행하겠습니다.
자 이제 네이버금융의 주식데이터를 수집하도록 하겠습니다.
저는 삼성전자의 주식데이터를 크롤링하였습니다.
BS4로 크롤링을 진행했습니다.
1. URL준비 - 페이지를 넘길 수 있도록 한번에 준비
base_url = 'https://finance.naver.com/item/sise_day.nhn?code=005930&page='
수집할 주식 데이터 2. 우리가 수집할 영역 확인
page source res = requests.get(base_url) html = BeautifulSoup(res.content,'html.parser') table0 = html.find('table',{'class':'type2'})3. 컬럼명으로 지정할 text를 추출
cate0 = table0.find_all('th') cate = [] for i in range(len(cate0)): if i == 2: cate.append(cate0[i].text) cate.append('상승/하락') else: cate.append(cate0[i].text)
Columns 4. 해당 주식의 주가정보 추출

주가정보 stock = [] #한 리스트 안에 여러개의 리스트 형식으로 한 행씩 들어가도록 for i in range(len(main0)): stock2 = [] a = main0[i].find_all('td') #테이블의 main text추출 for j in range(len(a)): if j == 2: #3번째 리스트 요소가 수치와 text가 혼합되어 있는 형태이므로 조건식 코드 p = re.compile('[0-9]') aa = ''.join(p.findall(a[j].text)) stock2.append(aa) bb = a[j].find('img')['alt'] stock2.append(bb) else: aa = a[j].text stock2.append(aa) stock.append(stock2)
주가정보 5. 수집한 주가 정보와 컬럼을 이용하여 DF화
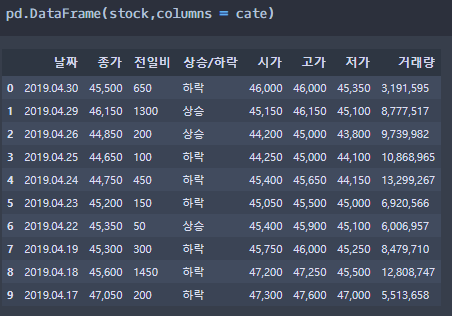
6. 데이터의 분석을 위해서 연속형 수치로 변환시켜줌 (현재는 각 데이터가 문자열로 되어 있음) 그리고 나서 변동폭을 한번 구해보자
stock_data2.iloc[:,[1,2,4,5,6,7]] = stock_data2.iloc[:,[1,2,4,5,6,7]].astype('float64') #변동폭 계산 stock_data2['변동폭'] = stock_data2['고가']-stock_data2['저가']지금까지 주식데이터를 활용하기 위한 데이터를 수집하는 작업까지 진행했습니다.
다음 포스팅은 해당 주식 데이터를 이용하여 상관분석 및 선형회귀, 예측 분석을 진행하도록 하겠습니다.
따라서 최종적으로 여러 지표들도 크롤링하여 퀀트투자를 하기 위한 최적의 주가데이터를 찾아보고 이를 통해서 검증하는 것까지 진행할 예정입니다. 감사합니다.
'ML, DL & Python > 주식데이터를 활용한 분석' 카테고리의 다른 글
주가 이동평균선을 활용한 시각화 및 최적의 매수시점 찾기 (0) 2019.06.10 기업 재무제표 크롤러 (8) 2019.06.10