-
주가 이동평균선을 활용한 시각화 및 최적의 매수시점 찾기ML, DL & Python/주식데이터를 활용한 분석 2019. 6. 10. 20:24
이번 포스팅은 각 기업의 주가 데이터를 활용하여 이동평균선을 구하고 이동평균선을 이용하여 최적의 주식 매수시점을 분석해보겠습니다.
주가 이동평균선은 n일 뒤의 대략적인 수익률을 알 수 있는 선입니다. 즉, 이동평균선은 "일정 기간 동안의 주가를 산술 평균한 값인 주가 이동평균을 차례로 연결해 만든 선"으로 정의한 것입니다.
이동평균선을 그리려면 먼저 여러개의 주가이동평균 값이 필요합니다. 여기서 말하는 주가이동평균이란 일정기간의 주가를 산술 평균한 값을 말합니다. 만일 parameter에서 window=5인 것은 5일 주가이동평균을 말하고 이를 연결한 선이 5일 주가이동평균 선입니다. (window = 120 -> 120일 주가이동평균)
주가이동평균선은 시장의 전반적인 주가 흐름을 판단하고 향후 주가의 추이를 전망하는데 자주 사용되는 기술지표입니다. 특히 주가이동평균선은 5일 20일 60일 120일 이동평균선이 서로 교차하게 되는데 이를 cross라고 부르며 이시점이 매우 중요한 매매시점이러고 생각하면 됩니다.
그럼 매매시점은 어떻게 나뉘는 것일까요? 여러분들도 많이 알고 계신 것처럼 주식은 사고 팔 수 있는 유가 증권입니다.여기서 주식을 사는 것은 "매수"라고 하고 주식을 파는 것을 "매도"라고 합니다. 이동평균선을 통해서 최적의 매수, 매도를 구분할 수 있는 것은 각 이동평균선끼리 접하는 지점으로 파악할 수 있습니다.
예를 들어 20일 주가이동평균선과 60일 주가이동평균선으로 비교해보겠습니다. 20일 주가이동평균선과 60일 주가이동평균선이 접하는 접점으로부터 시간이 지날수록 주가가 오르는 추세라면 해당 지점은 Golden Cross지점으로써 주식을 매수하기에 가장 최적인 시점이 됩니다.
반대로 위의 접점으로부터 시간이 지날수록 주가가 내려가는 추세라면 해당 지점은 Bad Cross지점이라고 말하며 주식을 매도하기에 가장 최적인 시점이 됩니다.
저는 이번에 이동평균선을 이용하여 시각화를 하고 가장 최적의 매수 시점과 최적의 매도 시점을 즉, golden cross, bad cross 지점을 찾는 것을 목표로 분석을 진행해보도록 하겠습니다.
1. 주가 데이터 불러오기
주가 데이터를 수집하기 위해서 python library인 finance datareader 라이브러리를 사용하도록 하겠습니다.
라이브러리를 다루는 법과 설명을 잘 풀어놓은 블로그 입니다. 참고바랍니다.
FinanceDataReader 사용자 안내서
FinanceDataReader 사용자 안내서
financedata.github.io
저는 우리나라기업인 LG이노텍의 주가데이터를 불러왔습니다. 여러분들은 분석을 진행할 때 꼭 LG이노텍 주가데이터가 아니여도 됩니다. 왜냐하면 데이터의 형식이 모든 기업마다 똑같기 때문입니다.
df = fdr.DataReader('011070','2016') #LG이노텍 종목코드 : 011070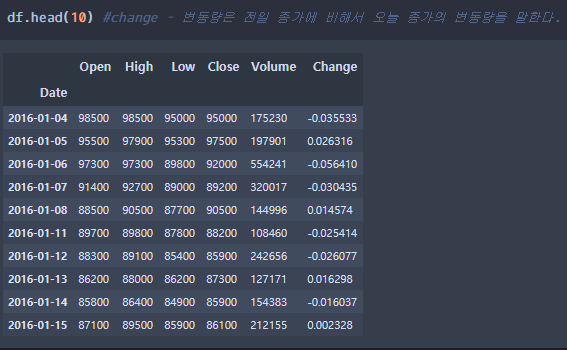
LG이노텍 주가정보 2. 해당 주가의 이동평균선 구하기
이제 주가의 이동평균선을 구해보겠습니다. 이동평균선을 각 날짜의 'Close' 변수를 사용해서 구해보겠습니다.
5일 주가이동평균을 구하는 공식을 통해서 예를 들어 보겠습니다.(간단한 산술평균)
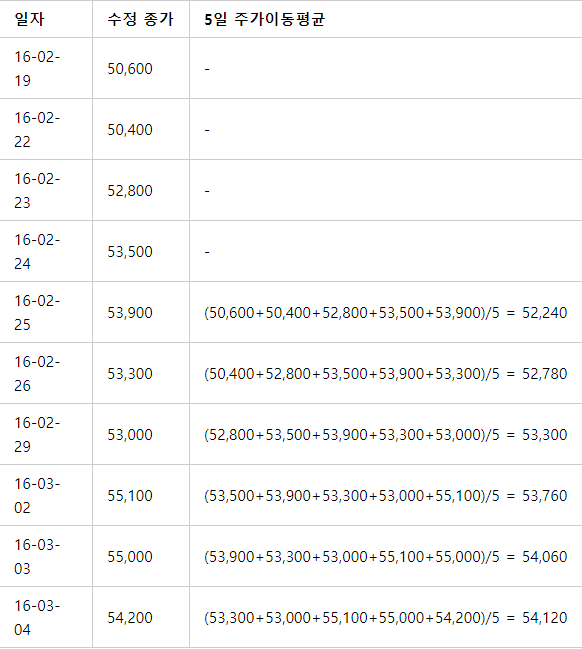
출처 : https://wikidocs.net/4373 생각하는 것보다 더 쉽죠??
그럼 이 공식을 통해서 python에서 구해보겠습니다.
ma5 = df['Close'].rolling(window=5).mean() #5일 주가이동평균선 구하는 법 #.rolling(window=n) - n은 n일 주가이동평균선을 뜻하며 위의 코드는 5일동안의 주가를 각 날짜마다 묶어주는 것입니다. #.mean() - 묶인 n일 만큼의 데이터를 산술평균하라는 명령어 df['MA5'] = ma5 #구한 5일 주가이동평균한 데이터를 "MA5"라는 새로운 변수로 넣어줍니다.마찬가지로 20일, 60일, 120일의 이동평균선을 구해보겠습니다.
ma_ls = [20,60,120] for i in range(len(ma_ls)): a = df['Close'].rolling(window=ma_ls[i]).mean() df['MA'+str(ma_ls[i])] = a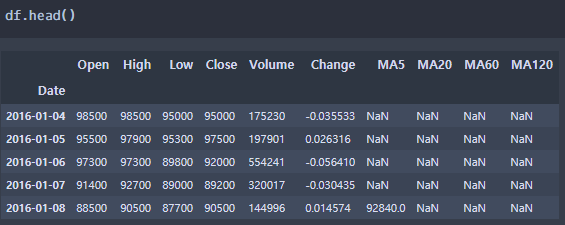
이동평균선 데이터 3. 이동평균선을 활용한 시각화
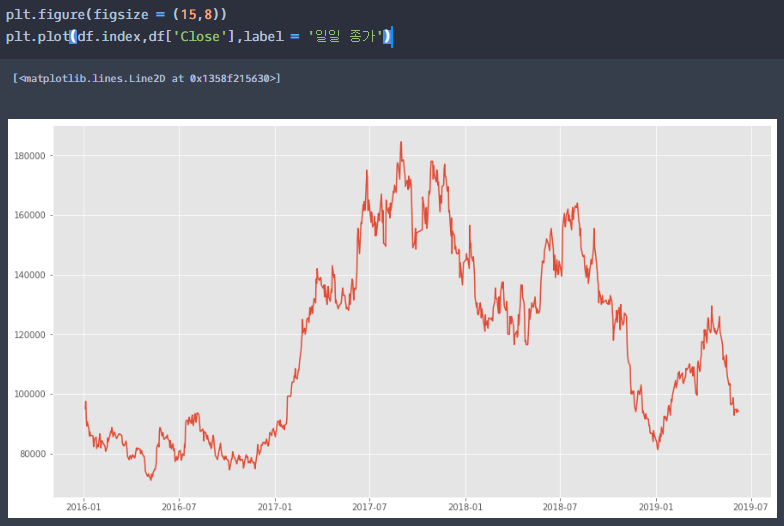
이동평균선이 아닌 해당 기업의 종가로 시각화 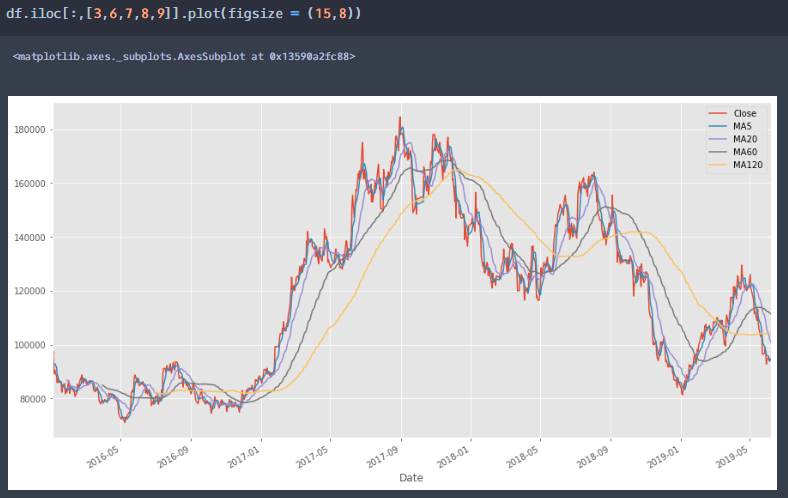
각 이동평균선과 함께 시각화 위의 시각화를 통해서 이동평균선의 window가 높아질수록 즉, 이동한 일수가 높아질수록 점점 smooth line에 가까워지는 것을 알 수 있습니다.
4. 이동평균을 통해서 최적의 주식 매매시점 탐색
자 이제 주식의 이동평균선을 통해서 주식의 최적 매매시점을 탐색해보도록 하겠습니다.
위의 이동평균선 그래프를 보시다시피 이동평균선끼리 접하는 점들이 많은 것을 확인할 수 있습니다. 이러한 접점들이 모두 golden cross ,bad cross가 될 수 있습니다.
먼저 저는 연산을 위해서 데이터에서 결측치를 모두 제외하고 분석을 시작했습니다. 그리고 20일의 주가이동평균데이터와 60일 주가이동평균데이터를 활용하여 코딩했습니다.
df.dropna(replace=True,axis=0) #데이터 결측치 제거 date_index = abs(df['MA20']-df['MA60']).sort_values().head(10).index #해당 주식의 20일 이동평균과 60일 이동평균을 이용하여 구한 최적의 매매시점은 다음과 같다.(date_index) #여기서 반환해주는 날짜는 + - 1일을 기준으로 ma20과 ma60이 교차하는 날짜인 즉, cross 날짜가 된다.현재 date_index는 접점을 찾기 위해서 작성한 코드이다. 이제 date_index데이터를 활용하여 최적의 매수시점과 매도시점을 추출하는 코드를 작성해보자.
5. Golden Cross, Bad Cross를 찾는 알고리즘 작성
이제 함수를 만들어 볼 것인데 주식을 매수한 혹은 매도한 시점부터 지니고 있을 기간을 파라미터로 두고 (파라미터는 3개월, 6개월, 9개월) 각 기간별로 최적의 매수시점을 구하는 함수를 만들어 보겠습니다.
나머지 설명은 코드와 함께 주석을 달아 놓겠습니다.
''' 3개월 - +90일까지의 수익률 반환 - date(2018,4,1 ) - date(2018,1,1) 6개얼 - +180일 까지의 수익률 반환 - date(2018,6,30 ) - date(2018,1,1) 9개월 - +270일 까지의 수익률 반환 - date(2018,9,28 ) - date(2018,1,1) 예비용 일 수 1일 - date(2018,1,2 ) - date(2018,1,1) / 2일 - date(2018,1,3 ) - date(2018,1,1) 3일 - date(2018,1,4 ) - date(2018,1,1) ''' def MA_backtesting(month): #몇개월을 생각하고 주식을 매수하고 매도할 것인지 parameter if month == 3: #3개월의 날짜를 구한 것 delta = date(2018,4,1 ) - date(2018,1,1) elif month == 6: #6개월의 날짜를 구한 것 delta = date(2018,6,30 ) - date(2018,1,1) else:# 9개월의 날짜를 구한 것 delta = date(2018,9,28 ) - date(2018,1,1) revenue = pd.DataFrame({'date':[], 'revenue':[]}) for i in range(len(date_index)): #3개월/6개월/9개월만큼의 수익률을 구하는 과정에서 만일 3개월/6개월/9개월 뒤의 날짜가 공휴일 #이거나 주말이여서 주식시장이 오픈을 하지 않는 것을 대비해서 무조건 산출할 수 있는 예를들어 #금요일이면 +3일 - 월요일 / 토요일이면 +2일 - 월요일 /일요일이면 +1일 - 월요일 #로 봤을 때 +3일까지의 대비변수를 마련해 놓으면 따로 예외처리하지 않고도 무조건 #결과를 도출할 수 있다. day1 = date(2018,1,2 ) - date(2018,1,1) #예비1일 day2 = date(2018,1,3 ) - date(2018,1,1) #예비2일 day3 = date(2018,1,4 ) - date(2018,1,1)#예비3일 #예외처리로 1일~3일까지 더할 수 있는 코드를 짜서 Error를 피한다. try: a = df.loc[date_index[i] + delta,'Close'] except: try: a = df.loc[date_index[i]+ delta+day1,'Close'] except: try: a = df.loc[date_index[i]+ delta+day2,'Close'] except: a = df.loc[date_index[i]+ delta+day3,'Close'] #a = date_index 즉, 접하는 지점으로부터 알고리즘 사용자가 지정한 날을 더한 날짜의 종가를 구한다 b = df.loc[date_index[i],'Close'] #date_index의 날짜의 종가데이터를 추출 revenue0 = a / b #수익률 및 손실률 insert_data = pd.DataFrame({'date':[date_index[i]], 'revenue':[revenue0]}) revenue = revenue.append(insert_data) revenue.index = range(len(revenue)) acc_date0 = revenue.sort_values('revenue',ascending=False)['date'].iloc[0]#최대 수익률의 날짜 acc_date00 = revenue.sort_values('revenue',ascending=False)['date'].iloc[len(revenue)-1]#최대 손실률의 날짜 try: a_df = df.loc[acc_date0:acc_date0+delta,'Close'] except: try: a_df =df.loc[acc_date0:acc_date0+delta+day1,'Close'] except: try: a_df = df.loc[acc_date0:acc_date0+delta+day2,'Close'] except: a_df = df.loc[acc_date0:acc_date0+delta+day3,'Close'] #a_df = 최대이익이 날 수 있는 접점날짜부터 알고리즘 사용자가 정한 날까지의 종가 데이터 try: b_df = df.loc[acc_date00:acc_date00+delta,'Close'] except: try: b_df =df.loc[acc_date00:acc_date00+delta+day1,'Close'] except: try: b_df = df.loc[acc_date00:acc_date00+delta+day2,'Close'] except: b_df = df.loc[acc_date00:acc_date00+delta+day3,'Close'] #b_df = 최대손실이 날 수 있는 접점날짜부터 알고리즘 사용자가 정한 날까지의 종가 데이터 plt.subplot(121) a_df.plot(figsize=(15,8))#이익률 그래프 plt.subplot(122) b_df.plot(figsize = (15,8),c='b') #손실률 그래프 acc_date = str(revenue.sort_values('revenue',ascending=False)['date'].iloc[0]) acc_revenue = str(revenue.sort_values('revenue',ascending=False)['revenue'].iloc[0]) acc_date2 = str(revenue.sort_values('revenue',ascending=False)['date'].iloc[len(revenue)-1]) acc_revenue2 = str(revenue.sort_values('revenue',ascending=False)['revenue'].iloc[len(revenue)-1]) print('Golden Cross') print('이동평균선을 이용하여 고객님에게 맞는 최적의 매수시점은 ' + acc_date + '입니다.') print('이동평균선을 이용하여 최적의 매수시점에 주식을 매수하고 '+ str(month) + '개월 뒤에 매도했을 때' + acc_revenue+'배의 수익을 얻을 수 있습니다.\n\n\n' ) print('Bad Cross') print('이동평균선을 이용하여 고객님에게 맞는 최적의 매도시점은 ' + acc_date2 + '입니다.') print('이동평균선을 이용하여 최적의 매도시점에 주식을 매도하지않으면 '+ str(month) + '개월 뒤에 매도했을 때' + acc_revenue2+'배의 손실을 얻을 수 있습니다.' ) return revenue.sort_values('revenue',ascending =False)결과를 확인해봅시다.
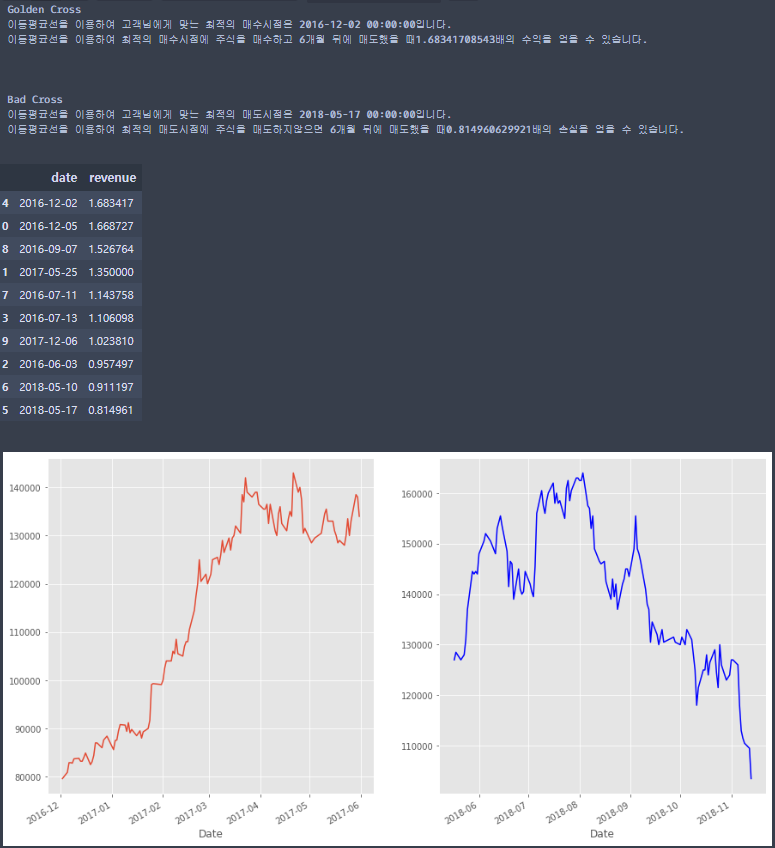
알고리즘 결과 Golden Cross / Bad Cross를 알 수 있다.
'ML, DL & Python > 주식데이터를 활용한 분석' 카테고리의 다른 글
기업 재무제표 크롤러 (8) 2019.06.10 주식데이터 크롤링 (0) 2019.05.19