-
기업 재무제표 크롤러ML, DL & Python/주식데이터를 활용한 분석 2019. 6. 10. 18:58
이번 포스팅은 기업의 재무제표를 수집할 수 있는 크롤러를 만들어보겠습니다.
기업의 재무제표는 기업의 현 상황 및 앞으로의 일어날 수 있는 일을 예측할 때 중요하게 사용되는 변수입니다. 따라서 주식에서 굉장히 중요하다고 볼 수 있는 각 기업별 재무제표를 수집하여 유용한 곳에 사용하고자 크롤러를 만들었습니다.
기업의 재무제표는 "네이버 금융"에서 종목코드를 검색하면 종목코드에 맞는 기업의 재무제표를 확인할 수 있습니다.
바로 시작해보겠습니다.
1. "네이버 금융" 접속
네이버 금융
국내 해외 증시 지수, 시장지표, 펀드, 뉴스, 증권사 리서치 등 제공
finance.naver.com
여기서 기업의 재무제표를 수집하는 크롤러를 만들 것
아무 종목코드나 입력하고 재무제표가 있는 부분의 "더보기"를 클릭하고 확인해보면 특이점을 확인할 수 있다.

재무제표 URL url을보면 확인할 수 있듯이 ?code=005300부분에서 저 코드부분만 계속 바꿔주면 서로 다른 기업의 재무제표를 볼 수 있는 것이다.
예를 들면 지금 005300은 "롯데 칠성"의 종목코드인데 저부분만 034220으로 바꿔주면 LG디스플레이의 재무제표로 접속할 수 있는 것이다.
2. 검색창에 아무 종목코드를 입력하고 수집영역 확인
아무 종목코드나 회사명을 입력하여 데이터 수집 영역을 확인해본다.

수집할 target데이터 오늘 우리가 크롤러를 만들어 수집할 데이터이다.
3. Page Source확인

앞의 데이터가 담겨져 있는 page source 페이지소스를 확인하면 위의 데이터가 frame구조안에 들어가 있는 것을 확인할 수 있다. frame 구조 안에 있으면 데이터를 정상적으로 수집할 수 없습니다. 따라서 frame구조 안으로 들어가야합니다. 하지만 들어가는 것은 어렵지 않으므로 바로 코딩을 합니다.
import requests # 웹 페이지 소스를 얻기 위한 패키지(기본 내장 패키지이다.) from bs4 import BeautifulSoup # 웹 페이지 소스를 얻기 위한 패키지, 더 간단히 얻을 수 있다는 장점이 있다고 한다. from datetime import datetime # (!pip install beautifulsoup4 으로 다운받을 수 있다.) import pandas as pd # 데이터를 처리하기 위한 가장 기본적인 패키지 import time # 사이트를 불러올 때, 작업 지연시간을 지정해주기 위한 패키지이다. (사이트가 늦게 켜지면 에러가 발생하기 때문) import urllib.request # from selenium.webdriver import Chrome import json import re from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys import datetime as dt def ttt(xx): name = xx base_url = 'https://finance.naver.com/item/coinfo.nhn?code='+ name + '&target=finsum_more' return base_url browser = Chrome() browser.maximize_window() browser.get(ttt('066571')) browser.switch_to_frame(browser.find_element_by_id('coinfo_cp')) #frame구조 안으로 들어가기frame구조로 들어갔으면 이제 frame안의 데이터에 접근 할 수 있습니다.
4. 우리는 이중에서 연별로 클릭을 해야하기 때문에 "연간" 부분을 클릭합니다.
#재무제표 "연간" 클릭하기 browser.find_elements_by_xpath('//*[@class="schtab"][1]/tbody/tr/td[3]')[0].click()5. page source 불러오기
html0 = browser.page_source #지금 현 상태의 page source불러오기 html1 = BeautifulSoup(html0,'html.parser') #기업 title불러오기 title0 = html1.find('head').find('title').text title0.split('-')[-1]6. 재무제표의 main 내용 불러오기
html22 = html1.find('table',{'class':'gHead01 all-width','summary':'주요재무정보를 제공합니다.'}) #재무제표 영역 불러오기6-1. 재무제표 영역에서 날짜 불러오기
thead0 = html22.find('thead') #날짜가 재무제표영역의 head부분에 들어가 있기 때문에 thead를 불러와야 한다. tr0 = thead0.find_all('tr')[1] #존재하고 있는 날짜대로 findall로 모두 수집 th0 = tr0.find_all('th') #날짜부분만 따로 저장 date = [] for i in range(len(th0)): date.append(''.join(re.findall('[0-9/]',th0[i].text)))6-2. 재무제표 영역에서 columns 및 본문 데이터 수집
tbody0 = html22.find('tbody') #tbody에 column으로 사용할 데이터와 본문 데이터가 모두 담겨져 있다. tr0 = tbody0.find_all('tr') #columns 수집 col = [] for i in range(len(tr0)): if '\xa0' in tr0[i].find('th').text: tx = re.sub('\xa0','',tr0[i].find('th').text) else: tx = tr0[i].find('th').text col.append(tx) #본문데아터 수집 td = [] for i in range(len(tr0)): td0 = tr0[i].find_all('td') td1 = [] for j in range(len(td0)): if td0[j].text == '': td1.append('0') else: td1.append(td0[j].text) td.append(td1)재무제표 모양을 보시면 날짜가 열에 있고 columns이 행에 있으므로 메인 데이터를 수집할 때 열인 date기준으로 수집이 된다. 따라서 컬럼으로 각 기업과 관련된 데이터로 사용하고 행으로는 date를 사용할 것이므로 "네이버 금융"의 재무제표를 전치한다고 생각하면 된다. 그래서 리스트로 수집한 본문데이터 자체를 전치를 해주는 과정을 거친다.
td2 = list(map(list,zip(*td)))
최종 수집 데이터 7. 최종, 재무제표 크롤러 만들기
browser = Chrome() browser.maximize_window() def stock_crawler(code): #code = 종목번호 name = code base_url = 'https://finance.naver.com/item/coinfo.nhn?code='+ name + '&target=finsum_more' browser.get(base_url) #frmae구조 안에 필요한 데이터가 있기 때문에 해당 데이터를 수집하기 위해서는 frame구조에 들어가야한다. browser.switch_to_frame(browser.find_element_by_id('coinfo_cp')) #재무제표 "연간" 클릭하기 browser.find_elements_by_xpath('//*[@class="schtab"][1]/tbody/tr/td[3]')[0].click() html0 = browser.page_source html1 = BeautifulSoup(html0,'html.parser') #기업명 뽑기 title0 = html1.find('head').find('title').text print(title0.split('-')[-1]) html22 = html1.find('table',{'class':'gHead01 all-width','summary':'주요재무정보를 제공합니다.'}) #date scrapy thead0 = html22.find('thead') tr0 = thead0.find_all('tr')[1] th0 = tr0.find_all('th') date = [] for i in range(len(th0)): date.append(''.join(re.findall('[0-9/]',th0[i].text))) #columns scrapy tbody0 = html22.find('tbody') tr0 = tbody0.find_all('tr') col = [] for i in range(len(tr0)): if '\xa0' in tr0[i].find('th').text: tx = re.sub('\xa0','',tr0[i].find('th').text) else: tx = tr0[i].find('th').text col.append(tx) #main text scrapy td = [] for i in range(len(tr0)): td0 = tr0[i].find_all('td') td1 = [] for j in range(len(td0)): if td0[j].text == '': td1.append('0') else: td1.append(td0[j].text) td.append(td1) td2 = list(map(list,zip(*td))) return pd.DataFrame(td2,columns = col,index = date)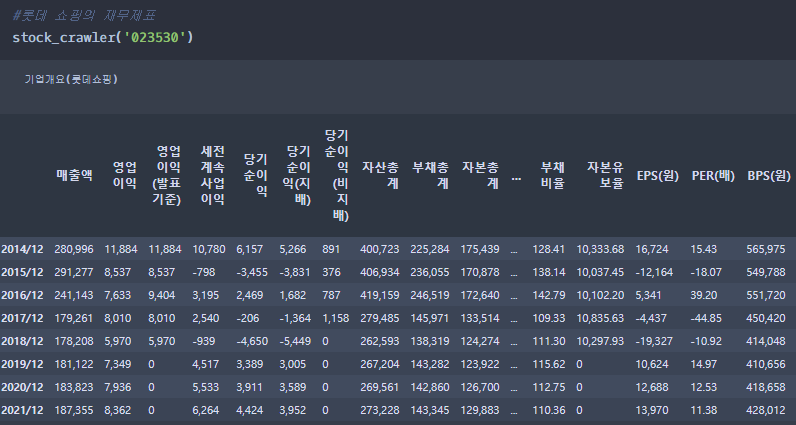
기업별 재무제표 크롤러 자 이제 만든 함수에 기업의 종목코드만 넣어주면 재무제표를 수집할 수 있습니다.
'ML, DL & Python > 주식데이터를 활용한 분석' 카테고리의 다른 글
주가 이동평균선을 활용한 시각화 및 최적의 매수시점 찾기 (0) 2019.06.10 주식데이터 크롤링 (0) 2019.05.19