-
Classification Evaluation MetricStatistics 2020. 7. 12. 20:57
이번 포스팅은 회귀 평가 척도에 대해서 알아봤던 저번 포스팅에 이어서 분류 문제에서 평가 척도로 이용하고 있는 지표들을 알아보고자 합니다.
바로 본론으로 들어가겠습니다.
분류 문제의 평가척도 종류는 다음과 같습니다.
1. Accuracy
2. F1-Score
3. Precision
4. Specificity
5. Sensitivity(Recall)
6. ROC-AUC
7. CSI
이렇게 단일척도에서 가지처럼 뻗어나가는 지표들이 존재하지만 각 지표의 큰 범주에 대해서 설명하고자합니다.
해당 챕터에서는 각각의 Metric에 대한 간단한 설명과 도출하는 방법, 그리고 어떤 상황에서 어떤 지표를 써야 알맞을지에 대하여 설명드릴 예정입니다.
먼저 지표에 대해서 알아보기 전 일전에 포스팅했던 Confusion Matrix와 곂치는 내용이 많기 때문에 링크를 달아 놓겠습니다.
Confusion Matrix의 손쉬운 이해
안녕하세요. 이번엔 봐도봐도 항상 헷갈릴 수 있는 Confusion Matrix 부터 AUC, ROC Curve에 대해서 설명해드리고자 합니다. 저희는 어떤 미지의 값을 예측할 때 예측에 대한 성능을 다양한 척도(Metric)로
shinminyong.tistory.com
1. Accuracy
Accuracy는 정확도로 전체 예측한 것 중에 올바른 예측을 얼마나 했는지를 지표로 구하는 것입니다. 즉, 양성으로 예측하거나 음성으로 예측한 것 중 실제로 양성과 음성을 모두 얼만큼 맞췄는지에 대한 지표인데요 공식은 다음과 같습니다.

ACC같은 경우에 예측에 대한 정확한 측정을 하기 위해서 주로 사용되는데요 하나 문제점이 있습니다. ACC를 평가 척도로 사용하기 위해서는 데이터 분포가 불균형 상태인지 확인해야하는데요. 이 말이 어떤 뜻이냐면 불균형한 데이터 상태에서 ACC로 측정하게 된다며 양성 / 음성에 몰려있는 데이터 분포로 인해서 ACC가 매우 높게 측정이 됩니다.
이러한 ACC의 단편적인 단점으로 인해서 저희는 평가할 지표를 설정할 때 데이터 분포, 데이터 타입 등을 고려하여 적절하게 선택해야 하며 이렇게 불균형한 데이터 상태에서는 주로 F1-Score를 활용하여 측정하곤 합니다.
2. F1-Score
F1 Score는 보통 불균형 분류문제에서 평가척도로 주로 사용됩니다. 데이터가 불균형한 상태에서 Accuracy로 성능을 평가하기엔 데이터 편향성이 너무 크게 나타나 올바르게 성능을 측정하기 힘들게 됩니다. 그렇기 때문에 F1 Score를 평가척도로 사용합니다.
그렇다면 왜 불균형 데이터 상태에서는 F1 Score를 이용할까요?
위에서 설명한 Sensitivity와 Precision을 이용하여 조화평균을 구하여 평가 척도를 구성했기 때문인데요.
다음의 그림을 보겠습니다.

두개 값의 크기가 서로 다른 형태를 나타내고 있는 불균형 상태이지만 이를 조화평균 함으로써 큰 값의 크기에 대한 가중치를 낮추고 작은 값에 더 맞춰주는 과정을 거쳐서 불균형 데이터일지라도 값의 크기 차이가 어느정도 상쇄되기 때문에 F1 Score는 불균형 데이터에서의 주요 척도로써 사용되고 있습니다.
수식은 다음과 같습니다.(헷갈리시면 안되는게 Sensitiviy는 Recall(재현도)와 같습니다.)

따라서 아무리 input class가 Positive에 맞춰져 있어 모델이 긍정에 대한 예측이 강한 분류기로 만들어질지라도 F1 Score로 평가 척도를 구해서 올바르게 분류가 되었는지 성능을 측정할 수 있습니다.
3. Precision, Sensitivity, Specificity
먼저 Precision은 정밀도라고도 하며 양성을 예측하거나 음성을 예측했을 때 얼마만큼 잘 맞췄는지에 대한 지표이며 수식은 다음과 같습니다.

두번재는 Sensitivity 재현도에 대한 설명입니다. 실제로 양성인 경우 양성을 얼마나 잘 예측했는지에 대한 지표이며 수식은 다음과 같습니다.

세번째는 Specificity입니다. 실제로 음성인 케이스에 음성을 얼마나 잘 예측했는지에 대한 지표이며 수식은 다음과 같습니다.

이 세가지의 지표를 이용해서 다음에 설명할 AUC에 대해서 설명을 드릴 수 있습니다. 주로 지금 설명한 지표들을 단일로 이용하는 경우는 많이 없으며 Cut-Off를 설정하거나 AUC를 위한 보조지표로써 많이 사용됩니다. 그럼 해당 지표는 왜 중요할까요? 일단 이 단일 지표들로 파생할 수 있는 평가 척도들이 많이 존재하며 아래의 예에서도 잘 고려해서 사용할 필요가 있습니다.
이 말이 어떤 뜻이냐면 "여기 암 검진을 받으러 온 한 사람이 있습니다. 이 때 1. 암이 걸리지 않은 사람에게 암에 걸렸다고 하는 것과 2. 암에 걸린 사람에게 암이 걸리지 않았다 라고 하는 것 중에 어떤 것이 가장 위험할까요?" 잘 생각해보면 답을 찾을 수 있을 것입니다!!
4. AUC
AUC는 위의 단일 지표들로 구성된 값이며 수식은 다음과 같습니다.

재현도와 1-특이도를 이용하여 ROC-Curve를 그린 뒤 아래 면적으로 AUC를 산출합니다.
AUC의 평가 기준은 다음과 같습니다.
0.5 ~ 0.6 : Fail
0.6 ~ 0.7 : Poor
0.7 ~ 0.8 : Fair
0.8 ~ 0.9 : Good
0.9 ~ 1.0 : Excellent
다른 지표들과 다르게 AUC는 왜 0.5부터 시작할까요? AUC가 0.5이하면 랜덤으로 맞추는 것보다 못맞추는 거라고 생각하시면 편하실겁니다. 따라서 0.5이상이 되어야 올바른 AUC를 측정했다고 생각하시면 될 것 같습니다
예를들어서

아래의 그림처럼 적절한 임계점(Cut-Off)를 구하여 AUC를 산정하는 것인데 0.5라는 것은 두개의 그래프가 완전히 곂쳐진 상태인 둘 중에 어떠한 값이든 랜덤으로 산출한다는 말이 되므로 0.5이상부터 올바른 지표라고 할 수 있겠습니다.
AUC는 분류문제에서 자주 평가척도로 사용되는 지표이기 때문에 이부분에 대해서는 Confusion Matrix부터 차례차례 공부하면서 익혀두시면 좋을 것 같습니다.
5. CSI
CSI는 보편적인 분류문제에서 사용되는 지표는 아니지만 이번에 프로젝트로 참여한 기상청 빅데이터 콘테스트에서 "결로현상"을 예측하기 위한 척도로써 사용된 지표여서 간단하게 소개해드리겠습니다.
CSI도 위의 지표들처럼 Confusion Matrix를 통하여 산출하는데요 특이하게 예측하고자 하는 특정 지표(양성/음성) 양성(양성을 기준으로 설명하겠습니다.)과 연관이 있는 모든 지표들 중에 실제로 양성을 맞췄는지에 대한 값을 구하는 것인데요. 수식을 살펴보겠습니다.
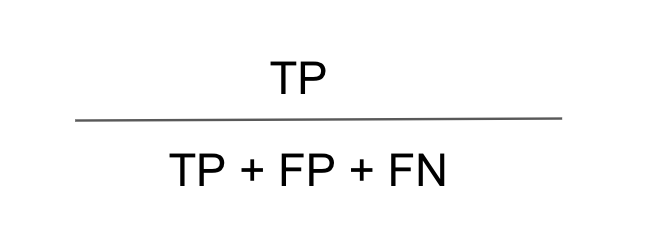
음성으로 예측했지만 실제로는 양성인 경우, 양성으로 예측했지만 실제로는 음성인 경우, 양성으로 예측했는데 실제로 양성인 경우 즉, 양성과 관련된 모든 지표들 중에 양성으로 예측하고 실제로 양성인 비율을 나타낸 값입니다.
다양한 대회에 참여하면서 처음 보았던 지표였는데요. 기상청에서는 예보에서 분류문제를 해결할 때 위와 같은 지표를 주로 사용한다고 합니다. 아마도 기상청에서는 예보에 대한 규정 및 규제를 높게 두어 정확도가 높은 예보를 해야하기 때문에 이러한 지표를 이용하지 않았을까 생각도 들었습니다.
따라서 해당 지표는 다른 ACC, AUC 등의 지표와는 다르게 값이 낮게 도출 되어 약 5-60% 이상만 되어도 높은 값을 도출했다고 할 수 있습니다. 보편적으로 사용되고 있지 않은 지표이지만 모델에 대한 규제를 강화해서 매우 정확한 값을 도출하고 싶을 때 이용 가치가 높은 지표라고 생각했습니다.
이렇게 다양한 분류 문제에서의 평가 척도들을 알아보았는데요. 이 외에도 다양한 평가 척도가 존재합니다. 저는 기본적이고, 주로 문제에서 보편적으로 사용되는 Metric에 대해서 소개해드렸기 때문에 제가 소개한 척도들에 대해서는 잘 숙지한 뒤 주어진 예측 문제를 해결하는게 좀 더 수월할 것이라고 생각됩니다. 저도 추가적으로 알게되거나 숙지가 필요한 지표들에 대해서는 덧붙여서 설명드리겠습니다. 읽어주셔서 감사합니다!
'Statistics' 카테고리의 다른 글
Machine Learning Imbalanced Data(불균형 데이터) (1) 2020.07.25 Regression Evaluation Metric (2) 2020.07.05 AUC와 ROC Curve (0) 2020.04.15 Confusion Matrix의 손쉬운 이해 (3) 2020.04.12