-
리그오브레전드 데이터 분석 - match data EDA(2)ML, DL & Python/Riot API를 활용환 데이터 분석 2020. 3. 15. 17:13
안녕하세요. 이번 포스팅은 저번에 이어서 연속형 데이터에 관한 분석을 진행해보도록 하겠습니다.
저번 포스팅을 간략하게 요약하자면 범주형 변수(1/0)에 대한 시각화를 진행했엇는데요. 결과적으로 우리가 알고 있던 자명한 사실들을 데이터적으로 확인할 수 있엇습니다.
본격적으로 연속형 데이터 분석을 진행하도록 하겠습니다.
아 그리고 해당 포스팅을 읽기전에 처음 읽으시는 분들은 1번째 포스팅을 먼저 읽어주시면 감사하겠습니다.(데이터를 받으실 수 있거든요 ㅎㅎ)
1. 데이터 불러오고 처리하기
이 부분은 이전 포스팅에서 자세히 다루고 있으므로 코드 한개에 담겠습니다.
import pandas as pd import pickle import matplotlib.pyplot as plt import numpy as np import sys import os from pandas.io.json import json_normalize import seaborn as sns #데이터 불러오기 lol_df = pd.read_pickle('/Users/sinmin-yong/GitHub/모든저장소데이터셋/파일 저장용(my-study)/롤17500개.pickle') lol_df.head() #a팀 b팀 분리 team_a_error = [] team_b_error = [] team_a = pd.DataFrame() team_b = pd.DataFrame() for i in range(len(lol_df)): if i % 1000 == 0: print(str(i)+'행 처리중') try: team_a = team_a.append(json_normalize(lol_df['teams'].iloc[i][0])) team_b = team_b.append(json_normalize(lol_df['teams'].iloc[i][1])) except: team_a_error.append(i) team_b_error.append(i) print(str(i)+'행에서 오류') pass # 팀a와 팀 b의 승패가 반대인지 데이터 정합성 검정 -모두 반대임을 확인 for i in range(len(team_a)): wf_valid = team_a['win'].iloc[i] if team_b['win'].iloc[i] != wf_valid: pass else: print(str(i)+'행 데이터 정합성 문제') #각 경기별 게임 시간 병합 lol_df = lol_df.drop(index = team_a_error) team_a['gameDuration'] = lol_df['gameDuration'].tolist() team_b['gameDuration'] = lol_df['gameDuration'].tolist() lol_df['gameDuration'].index = range(len(lol_df)) team_a['gameDuration'].index = range(len(team_a)) team_b['gameDuration'].index = range(len(team_b)) game_df = pd.concat([team_a,team_b],axis=0) #분석의 용이성을 위해서 타겟 데이터를 제외한 범주형 데이터를 인코딩 ''' True : 1 False : 0 ''' tf_mapping = {True:1,False:0} bool_column = game_df.select_dtypes('bool').columns.tolist() for i in bool_column: game_df[i] = game_df[i].map(tf_mapping) wl_mapping = {'Win':'Win','Fail':'Lose'} game_df['win'] = game_df['win'].map(wl_mapping) #게임 시간별 데이터 segment #n_tile로 게임시간을 분위수로 파악 game_part1 = game_df[game_df['game_time']>=30].sort_values('win') game_part2 = game_df[game_df['game_time']>=40].sort_values('win') game_part3 = game_df[game_df['game_time']<30].sort_values('win') game_part4 = game_df[game_df['game_time']<20].sort_values('win') #시각화 함수 def first_valid_visualize(df,target,variable): sns.factorplot(target,variable,data=df) plt.title(variable+' 변수의 승리확률') #plt.xticks(df[target]) plt.show()여기까지 완료했다면, 분석을 하기 위한 데이터 셋 구축은 완료하신겁니다.
2. 연속형 데이터 EDA
first_valid_visualize(game_df,'win','towerKills') plt.show()이전과 같이 연속형 데이터 시각화를 진행하겠습니다.

이긴 팀의 타워를 부신 개수가 평균적으로 많은 것을 확인할 수 있습니다.

이긴 팀의 바론을 처치한 횟수가 평균적으로 높은 것을 확인할 수 있습니다.

이긴 팀의 드래곤을 처치한 횟수가 평균적으로 높은 것을 확인할 수 있습니다.
해당 데이터 셋에서 경기별로 팀별로 몇킬이 나왔는지, 바위게는 어느팀에서 더 많이 먹었는지, 설치한 와드개수는 몇개인지 등의 데이터까지 있엇으면 더 재미있는 분석이 되었을텐데 해당 데이터는 없는게 아쉬웠습니다. 일단 해당 경기 id값과 연결되는 다른 데이터가 있는지 api를 더 확인해봐야겠습니다.
2-1. 경기 시간 segment 데이터별 EDA
그 다음은 경기 시간별 나눠놓은 4개의 데이터 셋을 바탕으로 분석을 진행해보겠습니다.
시각화를 하기 전에 먼저 각 경기 세그먼트별 연속형 데이터의 수치별 승패 비율을 확인하겠습니다.
ex) 20분 이하 게임에서 드래곤을 0개~n개 를 먹었을 때 승패 비율
#각 경기 시간 세그먼트 데이터별 sequence column의 수치별 승패 비율 차이 def sequence_var_inf(variable): global game_part1, game_part2, game_part3, game_part4 value1 = game_part4[variable].value_counts().keys().tolist() value2 = game_part3[variable].value_counts().keys().tolist() value3 = game_part1[variable].value_counts().keys().tolist() value4 = game_part2[variable].value_counts().keys().tolist() value1.sort() value2.sort() value3.sort() value4.sort() print('=============================') print('GameTime < 20 minute') print('=============================\n') for i in value1: try: a = game_part4[game_part4[variable]==i]['win'].value_counts().values[0] except: a = 0 try: b = game_part4[game_part4[variable]==i]['win'].value_counts().values[1] except: b = 0 print(variable+' 변수가 '+str(i)+' 일 때\n Win : {}\n Lose : {}\n'.format(a,b)) print('=============================') print('GameTime < 30 minute') print('=============================\n') for i in value2: try: a = game_part3[game_part3[variable]==i]['win'].value_counts().values[0] except: a = 0 try: b = game_part3[game_part3[variable]==i]['win'].value_counts().values[1] except: b = 0 print(variable+' 변수가 '+str(i)+' 일 때\n Win : {}\n Lose : {}\n'.format(a,b)) print('=============================') print('GameTime > 30 minute') print('=============================\n') for i in value3: try: a = game_part1[game_part1[variable]==i]['win'].value_counts().values[0] except: a = 0 try: b = game_part1[game_part1[variable]==i]['win'].value_counts().values[1] except: b = 0 print(variable+' 변수가 '+str(i)+' 일 때\n Win : {}\n Lose : {}\n'.format(a,b)) print('=============================') print('GameTime > 40 minute') print('=============================\n') for i in value4: try: a = game_part2[game_part2[variable]==i]['win'].value_counts().values[0] except: a = 0 try: b = game_part2[game_part2[variable]==i]['win'].value_counts().values[1] except: b = 0 print(variable+' 변수가 '+str(i)+' 일 때\n Win : {}\n Lose : {}\n'.format(a,b))함수를 작성한 뒤 결과값들을 확인해보겠습니다.
sequence_var_inf('dragonKills')
게임 경기가 길어질수록 드래곤 처치에 개수가 승리에 미치는 영향이 평균적으로 감소하는 것을 알 수 있습니다.

바론을 처치한 횟수 또한 경기 초반부들의 기록을 살펴보면 바론을 처치한 것이 게임 승리를 굳히는 역할을 하지만 경기가 길어질수록 한타 한번에 역전되는 경우가 많듯이 긴 경기일수록 처치한 바론 횟수가 승리에 미치는 영향이 감소하는 것을 확인할 수 있습니다.
심지어 30분이상, 40분이상의 경기기록으로 미루어보았을 때 바론처치 1번은 초반 경기들과 다르게 승리 패배 비율이 거의 차이 없는 것을 확인할 수 있습니다.

억제기 같은경우 1개가 깨졌다고해서 장기 게임에서는 큰 영향을 안주는 것을 확인가능하지만, 30분 이하의 게임들에서는 억제기 1개가 깨진 것에는 승패에 큰 영향을 보이는 것을 확인가능합니다.
타워를 부신 경우도 위의 결과들과 같은 양상을 보여 따로 보여드리진 않겠습니다. 한번 저 코드대로 실행해보시고 직접 결과를 확인해보시면 될 것 같습니다!
마지막으로 각 segment별로 해당 수치형 데이터들이 이긴 팀과 진팀에 어떤 비율로 반영되어 있는지 확인해보겠습니다.
def first_time_ratio(target,variable): global game_part1, game_part2, game_part3, game_part4 fig = plt.figure(figsize=(20,20)) fig.suptitle('게임 시간대별 승리 팀과 패배 팀의 ' + variable + ' 비율',size = 30) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(222) ax3 = fig.add_subplot(223) ax4 = fig.add_subplot(224) ax1.set_title('GameTime < 20 minute',size = 20) ax2.set_title('GameTime < 30 minute',size = 20) ax3.set_title('GameTime > 30 minute',size = 20) ax4.set_title('GameTime > 40 minute',size = 20) sns.factorplot(target,variable,data=game_part4,ax=ax1) #plt.title(variable+' 변수의 승리확률(GameTime < 20 minute)') #plt.show() sns.factorplot(target,variable,data=game_part3,ax=ax2) #plt.title(variable+' 변수의 승리확률(GameTime < 30 minute)') #plt.show() sns.factorplot(target,variable,data=game_part1,ax=ax3) #plt.title(variable+' 변수의 승리확률(GameTime >= 30 minute)') #plt.xticks(df[target]) #plt.show() sns.factorplot(target,variable,data=game_part2,ax=ax4) #plt.title(variable+' 변수의 승리확률(GameTime >= 40 minute)') #plt.xticks(df[target]) #plt.show() #plt.close(g.fig) #plt.show()이전 포스팅에서 시각화한 코드와 같은 코드입니다!
범주형 변수들의 결과와는 다른 결과가 도출되었는데요. 이는 마지막 부분에서 확인해보겠습니다.
first_time_ratio('win','dragonKills') plt.show()
범주형 변수들과의 결과와 다르게 드래곤을 처치한 횟수는 장기 게임으로 갈수록 높은 것을 확인할 수 있습니다.

타워를 부신 개수도 승리한 팀이 평균적으로 높습니다.
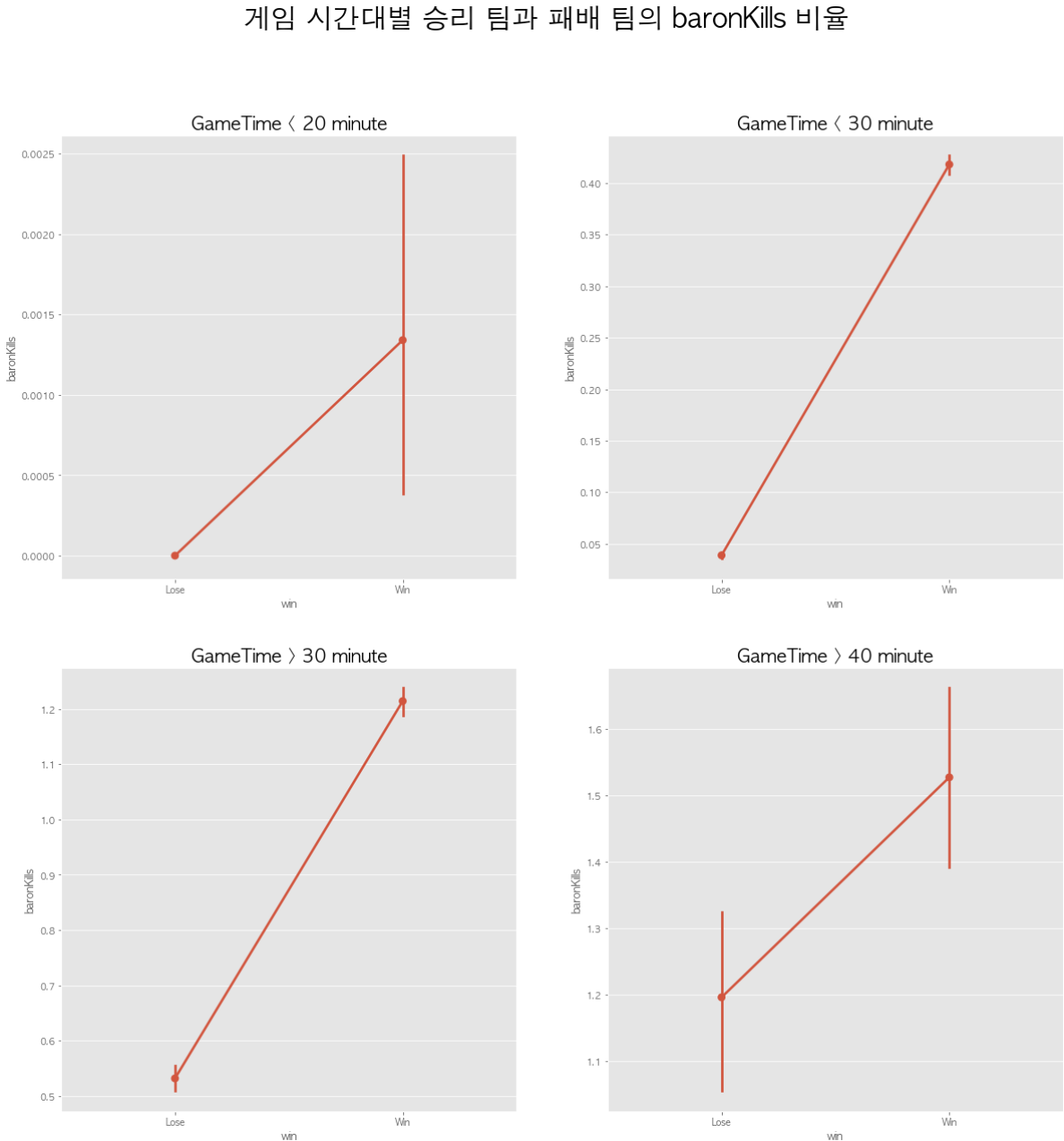
바론을 처치한 횟수도 영향력만 약해지지 승리한 팀에서 평균적으로 더 높은 것을 확인가능합니다.

억제기를 부신 개수 또한 승리한 팀에서 평균적으로 높은 것을 확인 가능합니다.
범주형 변수와 연속형 변수들과의 결과 차이가 왜 도출되었는지는 아마 몇몇분들은 알아채셨을 수도 있는데요. 범주형 변수는 처음으로 처치하거나 부신 여부를 나타내는 데이터인데 이는 어느정도 승리팀에서 높은 확률로 나타나는 것을 확인할 수 있지만 단순히 처음 처치했을 뿐이지 몇개를 뿌셧거나, 처치했는지는 알 수 없습니다.
그래서 first_column 데이터는 후반부 게임으로 갈수록 승리에 대한 영향력이 떨어지며 오히려 극 후반 게임일수록 지표가 역전되는 case도 이전 분석에서 확인할 수 있엇습니다.
그러나 이번 분석은 여부가 아니라 수치(몇개)를 분석하는 것이었으므로, 당연히 후반부 게임일지라도 이긴 팀에서 바론, 억제기, 타워 등의 변수의 평균이 높은 사실을 알 수 있던 것입니다.
하지만 후반부 게임일수록 한타 한 번에 역전되는 경우가 많기 때문에 영향력은 점차 감소되는 것을 승/패 비율, 평균으로 지금까지 확인했습니다. 참으로.. 데이터는 파고들고 파고들수록 새로운 사실들, 기존에 아는 사실이더라도 "와 이게 진짜네" 하는 결과들을 많이 보여주는 것 같습니다.
이번 분석에서 아쉬웠던 점은 중간에도 언급했지만, 더 경기에 대한 다양한 데이터가 없다는 점이었습니다. 이부분은 제가 모든 api를 고려해서 수집한 것이 아니기 때문에 좀 더 많은 부분(컬럼, 데이터)에 대해서 체크한 뒤 여러분들이 더 다양한 데이터로 분석하실 수 있도록 데이터를 구축해보겠습니다.
3. 다음 글 예고
다음은 해당 분석의 마지막 파트인 지금까지 분석했는 변수들이 승/패에 얼마만큼 관련이 있고, 영향을 끼쳤는지, 인과관계가 존재하는지를 상관분석과 Logistic Regression을 통해서 알아보겠습니다.
데이터가 필요하신 분들은 댓글에 이메일을 남겨주세요
'ML, DL & Python > Riot API를 활용환 데이터 분석' 카테고리의 다른 글
Riot API를 활용한 리그오브레전드(lol) 데이터 셋 구축(kaggle dataset) - User League/ item / champion / Ranked Games(랭겜) (5) 2020.03.28 리그오브레전드 데이터 분석 - Match Data Analytics(3) (3) 2020.03.15 리그오브레전드 데이터 분석 - match data EDA(1) (20) 2020.03.08 리그오브레전드 데이터를 활용한 승/패 예측 (6) 2019.06.02 라이엇 api를 활용한 리그오브레전드 데이터 수집 (55) 2019.06.01