-
리그오브레전드 데이터 분석 - match data EDA(1)ML, DL & Python/Riot API를 활용환 데이터 분석 2020. 3. 8. 18:47
안녕하세요 포스팅이 너무 늦은 것 같습니다 ㅠㅠ
취준에다가 회사일에다가... 이것저것 핑계를 일삼아 블로그 포스팅에 굉장히 소홀했던 것 같습니다...
그래서! 저도 이전에 했던 분석 히스토리가 가물가물한데 여러분들은 더 가물가물하겠죠?
죄송한 의미로 메일을 남겨주시면 분석한 경기데이터를 보내드리도록 하겠습니다.
(그랜드마스터의 경기 17500건의 데이터입니다. 데이터 변수에 대한 설명은 아래의 링크를 참고해주세요)
리그오브레전드 데이터를 활용한 승/패 예측
이전 포스팅에서 수집한 매치데이터를 이용하여 팀의 승/패를 예측해보겠습니다. 다들 teams 변수를 이용하여 데이터프레임화를 했던 것을 기억하시나요. teams데이터는 리스트안에 딕셔너리가 있는 구조로써 dict..
shinminyong.tistory.com
게임 데이터 분석은 그 어느 데이터보다 재미있게 분석할 수 있는 것 같습니다. 그게 지금 직접 하고 있는 게임이라면 더욱이죠
그래서 저도 롤을 굉장히 좋아하는 사람으로써 이전의 분석부터 많은 재미를 가지고 분석하고 있는 것 같습니다.
이번 분석은 제목처럼 경기데이터의 여러 변수들을 이용하여 EDA를 진행할 예정입니다.
1. 데이터 불러오기
import pandas as pd import pickle import matplotlib.pyplot as plt import numpy as np import sys import os from pandas.io.json import json_normalize import seaborn as sns먼저 필요한 라이브러리들을 먼저 받아옵니다.
lol_df = pd.read_pickle('/Users/sinmin-yong/GitHub/모든저장소데이터셋/파일 저장용(my-study)/롤17500개.pickle') lol_df.head()그 다음 제가 메일로 보내드릴 데이터인데 해당 데이터를 주피터로 파싱합니다.

자 정상적으로 데이터를 받아왔는지 확인이 완료되었습니다!
2. raw데이터에서 분석할 데이터로 전처리
#a팀 b팀 분리 team_a_error = [] team_b_error = [] team_a = pd.DataFrame() team_b = pd.DataFrame() for i in range(len(lol_df)): if i % 1000 == 0: print(str(i)+'행 처리중') try: team_a = team_a.append(json_normalize(lol_df['teams'].iloc[i][0])) team_b = team_b.append(json_normalize(lol_df['teams'].iloc[i][1])) except: team_a_error.append(i) team_b_error.append(i) print(str(i)+'행에서 오류') pass현재 lol_df 라는 데이터에는 승리한 팀과 패배한 팀이 분리되어 있습니다. 따라서 저희는 분석할 때 각 승리하고 패배한 팀별로 분석할 예정이니 이 둘을 나눠줍니다.
여기서 주의할점은 Json 중간중간 이빨 빠진듯이 null값인 데이터가 존재합니다. 그래서 이를 알기 위해서 try: except: 문으로 알아봅니다. 그리고 이렇게 비어있는 행들은 제외하고 데이터를 처리합니다.
# 팀a와 팀 b의 승패가 반대인지 데이터 정합성 검정 -> 모두 반대임을 확인 for i in range(len(team_a)): wf_valid = team_a['win'].iloc[i] if team_b['win'].iloc[i] != wf_valid: pass else: print(str(i)+'행 데이터 정합성 문제')저희는 분석할 때 각 승리하고 패배한 팀별로 분석할 예정이니 다음은 제대로 승리한 팀과 패배한 팀을 짝지어서 불어왔는지 데이터 정합성을 체크합니다.
앞으로 분석가로써 실무에서 데이터를 분석함에 있어 데이터 정합성 검정은 매우매우매우 중요하니 연습해보시길 바랍니다!
#각 경기별 게임 시간 병합 lol_df = lol_df.drop(index = team_a_error) team_a['gameDuration'] = lol_df['gameDuration'].tolist() team_b['gameDuration'] = lol_df['gameDuration'].tolist() lol_df['gameDuration'].index = range(len(lol_df)) team_a['gameDuration'].index = range(len(team_a)) team_b['gameDuration'].index = range(len(team_b))그 다음은 lof_df 데이터에서 각 경기당 시간이 얼마나 걸렸는지 데이터로 확인하기 위해서 gameDuration 컬럼을 양 팀에 붙여줍니다.
game_df = pd.concat([team_a,team_b],axis=0) game_df.head()음 제가 저번 포스팅에서 실수한 것이 있었는데 승패를 예측할 때 team_a나 team_b의 데이터 둘중에 하나만 가지고 학습을 시키고 승/패 예측을 했었습니다. 하지만 그럴 필요가 없었던 것이 사실 A팀과 B팀의 데이터는 달라서 두 팀의 데이터를 행결합하여 더 많은 데이터로 학습을 시켜 예측해서 결과의 신뢰성을 좀 더 높일 수 있었습니다. 약간의 아쉬움이...
따라서 이번에 분석을 할 때는 game_df에 두 팀의 데이터를 결합합니다.

#분석의 용이성을 위해서 타겟 데이터를 제외한 범주형 데이터를 인코딩 ''' True : 1 False : 0 ''' tf_mapping = {True:1,False:0} bool_column = game_df.select_dtypes('bool').columns.tolist() for i in bool_column: game_df[i] = game_df[i].map(tf_mapping) wl_mapping = {'Win':'Win','Fail':'Lose'} game_df['win'] = game_df['win'].map(wl_mapping)다음은 분석하기 용이하게 하기 위해서 논리형 데이터들을 모두 1,0으로 encoding해줍니다. 딱히 label encoding 함수로 할 필요가 없어 mapping을 이용해서 인코딩 했습니다.
3. EDA
3-0. 통계치 확인
먼저 승리 팀과 패배팀의 통계치를 확인해보겠습니다.
game_df[game_df['win']=='Win'].describe()[['towerKills','inhibitorKills','baronKills','dragonKills']]
승리팀의 통계치 game_df[game_df['win']=='Lose'].describe()[['towerKills','inhibitorKills','baronKills','dragonKills']]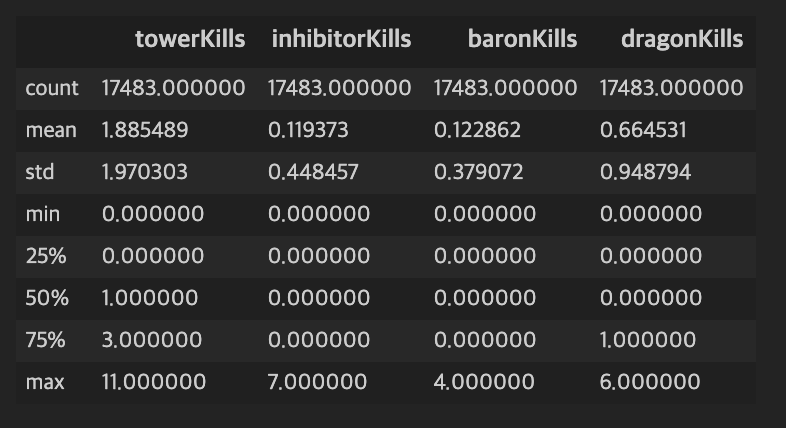
패배팀의 통계치 위의 통계값을 확인해보면 승리한 팀일수록 타워, 억제기, 바론, 드래곤의 처치 횟수가 평균적으로 높은것을 확인할 수 있습니다.
또한 아예 오브젝트 싸움이 일어나지 않고 항복에 의해서 게임이 끝나는 경우도 있기 때문에 승리팀의 표준편차가 더 큰 것도 확인할 수 있습니다.
3-1. 범주형 시각화
자 이제 통계 값도 확인해 봤으니 실제로 저 값들이 맞는지 그리고 저희가 통상적으로 알 수 있듯이 승리한 팀인 경우 여러 오브젝트에서 다 값이 높은지 확인해보겠습니다.
def first_valid_visualize(df,target,variable): sns.factorplot(target,variable,data=df) plt.title(variable+' 변수의 승리확률') #plt.xticks(df[target]) plt.show()시각화에 앞서 시각화 함수를 만들어줍니다. factorplot은 어떤 종속변수에 대하여 연속형 변수나 정수형변수의 확률값을 알려줍니다.
밑에서부턴 편의상 샘플 코드만 적고 시각화 결과들만 보여드리겠습니다.
first_valid_visualize(game_df,'win','firstBlood') plt.show()
승리한 팀일수로 퍼블낸 비율이 약 20%p 더 높은 것을 확인할 수 있습니다. 이는 전반적인 게임에서 퍼블의 중요성이 어느정도 중요하다고 볼 수 있습니다.

승리한 팀일수록 첫 타워를 민 비율이 약 50%p 높은 것을 확인할 수 있습니다. 이 또한 전반적인 게임에서 첫 타워의 중요성을 보여줍니다.

승리한 팀일수록 첫 억제기를 민 비율이 약 60%p로 매우 높습니다. 첫 억제기는 게임의 승리에서 굉장히 중요한 것을 보여줍니다.

첫 바론 또한 승리한 팀이 패배한 팀보다 약 30%p 높아 승리에 중요한 요소임을 알 수 있습니다.

첫 드래곤도 약 40%p 차이로 승리에 중요한 요소입니다.

전령 또한 승리에 중요한 키 포인트임을 알 수 있습니다.
여기까지 확인해보았을 때 굉장히 저명한 사실들임을 알 수 있습니다.
당연히 먼저 죽이고, 먼저 오브젝트를 획득하는 것은 승리에 키포인트임을 누구든지 알 수 있을 것입니다.
하지만 이렇게 저명한 사실일지라도 데이터를 통해서 객관적으로 파악해볼 수 있는 것은 중요하다고 생각하고, 또한 이렇게 사실들을 검증해 나가는 것들에서 느끼는 재미는 아마 분석가 분들이라면 다들 공감하실겁니다!
3-2. 경기 시간 segment별 EDA
저는 이번에 이러한 생각을 해봤습니다.
롤을 하다보면 "후반가면 우리가 이겨" 내지는 "좀만 멘탈차리고 하자 이길 수 있어!" 등등의 말들을 굉장히 많이 하고는 합니다. 게임 후반으로 갈수록 이러한 오브젝트의 영향이 희석되는 경향이 있어 게임의 판도를 완전히 뒤집는 상황이 벌어지기도 하는데요, "과연 이러한 게임의 양상들을 데이터도 설명하고 있을까?" 라는 생각이 들어서 게임에 걸린 시간별로 데이터를 segment화하여 분석해보았습니다.
#n_tile로 게임시간을 분위수로 파악 #part1 game_df['game_time'] = game_df['gameDuration']/60 game_part1 = game_df[game_df['game_time']>=30].sort_values('win') game_part2 = game_df[game_df['game_time']>=40].sort_values('win') game_part3 = game_df[game_df['game_time']<30].sort_values('win') game_part4 = game_df[game_df['game_time']<20].sort_values('win')먼저 게임 시간을 20분 이하 게임, 30분 이하 게임, 30분 이상게임, 40분 이상 게임 의 4개의 세그먼트로 나눴습니다.
def first_time_ratio(target,variable): global game_part1, game_part2, game_part3, game_part4 fig = plt.figure(figsize=(20,20)) fig.suptitle('게임 시간대별 승리 팀과 패배 팀의 ' + variable + ' 비율',size = 30) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(222) ax3 = fig.add_subplot(223) ax4 = fig.add_subplot(224) ax1.set_title('GameTime < 20 minute',size = 20) ax2.set_title('GameTime < 30 minute',size = 20) ax3.set_title('GameTime > 30 minute',size = 20) ax4.set_title('GameTime > 40 minute',size = 20) sns.factorplot(target,variable,data=game_part4,ax=ax1) #plt.title(variable+' 변수의 승리확률(GameTime < 20 minute)') #plt.show() sns.factorplot(target,variable,data=game_part3,ax=ax2) #plt.title(variable+' 변수의 승리확률(GameTime < 30 minute)') #plt.show() sns.factorplot(target,variable,data=game_part1,ax=ax3) #plt.title(variable+' 변수의 승리확률(GameTime >= 30 minute)') #plt.xticks(df[target]) #plt.show() sns.factorplot(target,variable,data=game_part2,ax=ax4) #plt.title(variable+' 변수의 승리확률(GameTime >= 40 minute)') #plt.xticks(df[target]) #plt.show() #plt.close(g.fig) #plt.show()그 다음 이에 관한 시각화 코드를 작성했습니다. 해당 코드는 각 게임 시간별 데이터를 위의 시각화와 똑같이 factorplot으로 표현했습니다.
first_time_ratio('win','firstBlood')
분석해보면서 재밌는 순간들이 바로 이런 것 같습니다. 역시 장기적인 게임으로 갈수록 점점 승리한팀의 퍼블낸 비율이 희석되나 싶더니 결국 40분이 넘어가면 오히려 승리한팀에서 퍼블 비율이 낮은 것을 확인할 수 있습니다. 이는 원래 퍼블을 패배한 팀에서 내서 유리하게 상황을 가져가다가 결국에 장기 게임으로 가면서 패배한 경우를 보여줍니다.

역시 장기 게임을 가더라도 승리한 팀의 첫 억제기를 부신 비율이 높은 것으로 봐서 첫 억제기는 위의 단일 시각화가 보여주듯이 승리 영향에 굉장히 높은 지표를 보여줍니다. 하지만 점점 영향도가 희석되기는 합니다.

첫 드래곤 역시 먹은 팀이 유리한 상황을 가져가지만 시간이 긴 게임일수록 점점 큰 영향을 미치지 않는 것을 확인할 수 있습니다.

바론은 드래곤보다 더욱 지표의 차이를 확연하게 보여주는데, 첫 바론의 영향은 40분 이상 게임일수록 큰 영향을 발휘하지 못한다는 것을 확인할 수 있습니다.

첫 전령 역시 같은 결과를 보여줍니다.
이처럼 게임이 길어질수록 저희가 하는 말들은 틀린말은 아닌 것을 확인할 수 있습니다. 물론 저희가 원하는대로 게임이 길어질수는 없지만(멘탈나간 팀원, 탈주한 팀원 등....) 그래도 게임이 길어질수록 불리한 팀에게 유리한 상황이 벌어질 수 있다는 것을 데이터를 통해서 확인했기 때문에 멘탈 꽉 잡고 게임해보시길 바랍니다 ㅎㅎ(저도 멘탈 꽉 잡겠습니다.)
그리고 이번 분석을 통해 깨달을 수 있엇던 점은 여러 의사소통을 하거나 말을 할 때 Data-Driven하게 얘기할 수 있다는 것을 알게 되었는데요. 그냥 뻔하게 자명한 사실이라고 단순히 말하는 것이 아니라 실제로 분석해보고 데이터가 말해주는 것들을 이와 같은 시각화라던지 통계분석을 통해서 보여줄 수 있는 그게 바로 분석가의 중요한 역량이 아닐까 생각이 많이 드는 분석이었습니다.
4. 다음 글 예고
이번 포스팅들은 보여드리고 싶은 것이 너무 많아서 총 3파트로 나눠서 진행할 예정입니다.
이번 내용들은 범주형 변수의 시각화까지만 보여드렸는데 다음 파트에서는 연속형 변수(타워킬, 드래곤킬, 바론킬, 억제기킬 등)의 시각화를 통해서 차이를 보여드리고 연속형 변수의 개수별로 게임 길이 별로 승리와 패배의 빈도 차이는 얼만큼 차이가 있는지 보여드리겠습니다.
part3에서는 승리와 패배를 예측하는 포스팅을 했었는데 이에 관해서 종속변수 승리와 패배, 독립변수들간의 상관분석 및 독립변수들이 종속변수들에 실제로 영향을 주는지 인과분석을 Logistic Regression을 통해 알아볼 예정입니다. 그럼 조만간 돌아오겠습니다.
해당 데이터를 바로 분석해보실 분들은 아래의 제가 캐글에 구축해 놓은 데이터셋을 다운로드 받아서 사용해주세요!!
1. 챌린저, 그마, 마스터 랭크게임(바로 분석할 수 있도록 정교하게 데이터 셋 구축한 버전)
www.kaggle.com
2. 챌린저, 그마, 마스터 경기 시작 후 10분, 15분까지의 게임 데이터(바로 분석할 수 있도록 정교하게 데이터 셋 구축한 버전)
www.kaggle.com
3. 챌린저, 그마, 마스터 랭크게임(모든 경기 데이터가 다 담겨있지만 전처리가 필요한 데이터 셋)
www.kaggle.com
4. 챔피언, 아이템에 대한 정보
www.kaggle.com
'ML, DL & Python > Riot API를 활용환 데이터 분석' 카테고리의 다른 글
Riot API를 활용한 리그오브레전드(lol) 데이터 셋 구축(kaggle dataset) - User League/ item / champion / Ranked Games(랭겜) (5) 2020.03.28 리그오브레전드 데이터 분석 - Match Data Analytics(3) (3) 2020.03.15 리그오브레전드 데이터 분석 - match data EDA(2) (3) 2020.03.15 리그오브레전드 데이터를 활용한 승/패 예측 (6) 2019.06.02 라이엇 api를 활용한 리그오브레전드 데이터 수집 (55) 2019.06.01