-
감정분석 모델을 이용한 네이버 평점 긍/부정 분석ML, DL & Python/감정분석 2019. 6. 8. 17:47
안녕하세요. 이번 포스팅은 저번에 만들었던 감정분석 모델을 활용하여 "네이버 영화"에서 영화를 하나 골라 사람들이 남긴 평점과 별점을 이용하여 만들었던 모델이 얼마나 정확하게 만들었는지(타당성) 확인하고 긍/부정을 예측한 뒤에 ㅇ사람들이 남긴 각 평점과 비교를 해보겠습니다.
먼저 그러기 위해서는 네이버 영화의 사람들이 남긴 평점 정보를 수집해와야합니다.
1. 네이버 영화에서 수집할 영화 및 수집할 영역 찾기

이번 포스팅에서 수집할 영화 이번에 수집할 영화는 "엑스맨 : 다크피닉스"라는 영화의 데이터를 수집해보도록 하겠습니다.
수집할 카테고리는 평점 카테고리며 사람들이 남긴 댓글과 별점을 수집할 것입니다.
수집할 데이터를 확인해보면 다음과 같습니다.
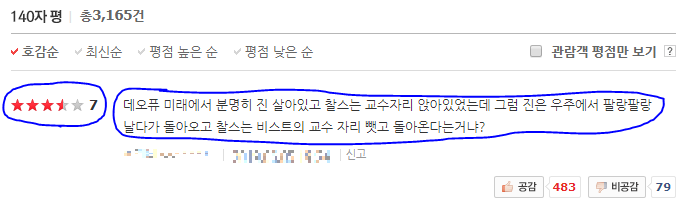
2. 셀레늄으로크롤링하기
네이버 영화에서 제가 필요로하는 정보가 html코드 상에서 iframe안에 들어가 있으므로 셀레늄을 통해서 데이터를 수집하겠습니다. 코드별로 주석을 달아 놓을테니 참고하시기 바랍니다.
base_url = 'https://movie.naver.com/movie/bi/mi/point.nhn?code=164125'#해당 영화의 평점을 수집할 수 있는 url browser = Chrome() #chrome web driver 실행 browser.maximize_window() #chrome web browser 최대화 browser.get(base_url) #지정해 놓은 url로 이동 browser.switch_to_frame(browser.find_element_by_id('pointAfterListIframe')) #iframe구조로 들어가기이제 본격적으로 데이터를 수집하도록 하겠습니다.
전체 평점 댓글이 3100여개정도가 있는데 시간관계상 1000개의 댓글만 수집하여 분석해보도록 하겠습니다.
#네이버 평점 데이터 1000개 수집 naver_movie = pd.DataFrame({'star_score':[], #columns만 있는 df만들기 'review':[]}) for page in range(0,100): #페이지를 100번만 이동 time.sleep(1) #1초의 시간 delay html0 = browser.page_source #selenuim에서 현재 있는 browser의 페이지 소스 불러오기 html1 = BeautifulSoup(html0,'html.parser') #bs4를 이용하여 html로 파싱하기 html2 = html1.find('div',{'class':'ifr_area basic_ifr'}) #댓글반응과 별점을 포함하고 있는 tag찾기 review0 = html2.find('div',{'class':'score_result'}).find_all('li')#각 댓글별로 list화 for i in range(len(review0)): #한페이지 내에서 모든 댓글을 수집하기 위한 반복문 star_score = review0[i].find('div',{'class':'star_score'}).find('em').text #별점 review = review0[i].find('div',{'class':'score_reple'}).find('p').text#댓글 insert_data = pd.DataFrame({'star_score':[star_score], 'review':[review]}) naver_movie = naver_movie.append(insert_data) #다음페이지로 넘어가기 if page == 0: browser.find_elements_by_xpath('//*[@class = "paging"]/div/a')[10].click() else: browser.find_elements_by_xpath('//*[@class = "paging"]/div/a')[11].click() naver_movie.index = range(len(naver_movie))#데이터 인덱스 정리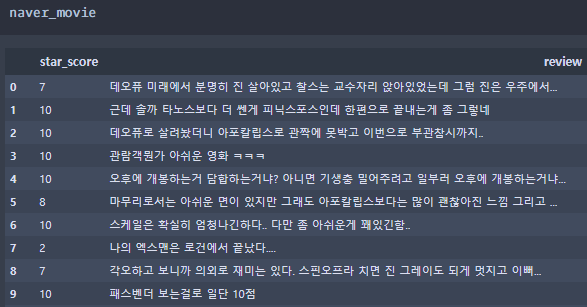
최종 결과 데이터 확인해보시면 별점과 사람들이 남긴 댓글이 잘 수집된 것을 보실 수 있습니다.
3. 모델에 넣기 위해서 dtype변경
naver_movie['star_score'] = naver_movie['star_score'].astype('float32') star_score_ls = naver_movie['star_score'].tolist()과연 별점별 분포는 어떻게 될까?
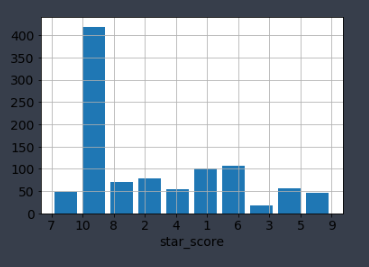
별점별 분포 10점이 압도적으로 많고 나머지 점수들의 비중은 거의 비슷한 것을 볼 수 있습니다.
4. 모델을 위한 범위 라벨링
이제 모델에 넣기 위한 y변수를 만들기 위해서 별점 범위를 이용하여 labeling을 해야합니다.
분석 목적이 평점 댓글을 통해서 해당 댓글이 긍정을 나타내는지 부정을 나타내는지 이므로 y변수는 별점 데이터를 이용하여 별점 범위를 가지고 라벨링이 필요합니다.
저는 분석을 위해서 별점이 7점 이상이면 긍정인 반응, 7점 미만이면 부정인 반응이라고 생각하고(실제로 6점인 사람들은 댓글을 좋지 못하게 단 것을 확인했음.) 라벨링을 했습니다.(긍정 : 1 , 부정 : 0)
#별점이 7점 이상인 경우에는 긍정인 리뷰 7점보다 낮으면 부정의 리뷰라고 생각한다. def star_score_evaluate(starscore): if starscore >= 7: return 1 else: return 0 naver_movie['NP'] = naver_movie['star_score'].apply(star_score_evaluate)#긍부정 여부 1,0으로 라벨링
긍정 반응 / 전체 반응 5. 학습된 모델로 네이버 댓글을 활용한 긍/부정 예측
def predict_pos_text2(text): token = tokenizing(text) #okt.pos로 토큰화한 단어를 정리 tf =term_frequency(token)#토큰화된 단어를 이용해서 가장 많이 등장하는 단어와의 빈도수 체크 data = np.expand_dims(np.asarray(tf).astype('float32'), axis=0) #np.expand_dims?? score = float(model.predict(data)) #새로운 데이터를 받으면 결과 예측해줌 if(score > 0.5): return 1 else: return 2 test_ls = [] #위 모델을 이용한 긍/부정 예측 데이터 리스트화 for i in range(len(naver_movie)): test_ls.append(predict_pos_text2(naver_movie['review'].iloc[i])) test_ls2 = [] #지금 긍정이 1 부정이 2로 되어 있는 구조이므로 정확도를 구하기 위해서 긍정1 / 부정0으로 바꿔줌 for i in range(len(test_ls)): test_ls2.append(2-test_ls[i])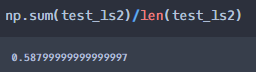
예측된 긍정반응 / 전체반응 위의 결과를 보시면 아주 놀라운 결과임을 알 수 있습니다. 저는 처음에 결과를 보고 눈을 의심했었는데요, 결과가 이상하다고 해도 무방할만큼 정확한 결과가 도출되었기 때문입니다.(긍정으로 예측한 갯수와 실제 긍정인 반응의 갯수가 같음)
하지만 생각해보면 학습된 모델에 넣어서 예측한 결과이므로 긍정 -> 부정 , 부정 -> 긍정 으로 예측할수도 있었던 것입니다. 따라서 그렇게 잘못 예측한 것이 얼마나 있는지 확인하기 위해서 코드를 만들어보았습니다.
6. 모델의 정확도 판단
모델의 정확도를 판단하기 위해서 정확도를 구해보았습니다. 예측한 y변수와 실제 y변수를 가지고 predict함수를 써도 되지만 직접 만들어 보았습니다.
acc=[] for i in range(len(naver_movie)): if naver_movie['NP'].iloc[i] == naver_movie['pred'].iloc[i]: acc.append(1) else: acc.append(0) np.sum(acc)/len(acc) #predict함수를 이용한 예측 #from sklearn.metrics import accuracy_score #accuracy_score(naver_movie['NP'].tolist(),naver_movie['pred'].tolist())
정확도 계산 도출 결과 네이버 평점의 긍/부정을 예측한 결과는 78%의 정확도를 가지는 것을 알 수 있습니다. 기존에 모델을 학습시켰던 데이터로 예측한 결과인 85%에는 못미치는 결과지만 어느정도 정확한 예측값인 것을 알 수 있습니다.
지금까지 영화리뷰 긍/부정 데이터를 이용하여 모델을 학습시키고 만든 모델을 이용하여 직접 수집한 데이터를 가지고 예측해보는 시간을 가졌습니다. 그리고 예측한 결과로 좋은 결과도 낼 수 있었습니다.
따라서 앞으로 해당 모델을 이용하여 여러 한국어로 된 반응들의 긍/부정을 예측하고 해당 모델에 더 정확한 데이터들을 추가하여 모델링을 정교하게 만들면 좋을 것 같습니다. 감사합니다.
'ML, DL & Python > 감정분석' 카테고리의 다른 글
감정분석 모델을 통한 네이버 평점 분석 (4) 2019.06.06