-
감정분석 모델을 통한 네이버 평점 분석ML, DL & Python/감정분석 2019. 6. 6. 19:36
안녕하세요 이번 포스팅은 감정분석을 통해서 네이버 평점으로 사람들이 영화를 평가해 놓은 것에 대해서 긍정 / 부정 평점인지 분석한 다음 실제로 사람들이 부여한 별점과 비교하여 얼마나 정확하게 사람들의 감정을 예측했는지 알아보도록 하겠습니다.
따라서 먼저 감정분석 모델을 만들고 데이터를 학습시켜 보겠습니다.
본 포스팅의 내용은 아래의 블로그를 참고하여 만들었습니다.
[Keras] KoNLPy를 이용한 한국어 영화 리뷰 감정 분석
이 포스트에서는 KoNLPy, nltk, Keras를 이용해서 한국어 영화 리뷰의 감정을 분석하는 방법에 대해 다룹니다.
cyc1am3n.github.io
데이터는 영화 리뷰 데이터(ratings_train.txt, ratings_test.txt)를 이용하겠습니다.
http://github.com/e9t/nsmc/ -> 데이터 다운로드
자 이제 감정분석 모델을 만들기 위해서 다운로드 받은 데이터를 학습시켜야합니다.
그러기 위해서는 모델에서 원하는 형식으로 데이터를 전처리 해야겠죠?
1. 데이터 불러오기
def read_data(filename): with open(filename, 'r') as f: #데이터 f 함수를 이용하여 불러오기 data = [line.split('\t') for line in f.read().splitlines()] #f 함수를 이용하여 먼저 줄별로 split한 데이터를 반복문을 통해서 띄어쓰기를 구분자로 split한 것을 리스트로 반환 # txt 파일의 헤더(id document label)는 제외하기 data = data[1:] return data train_df = read_data('ratings_train.txt') test_df = read_data('ratings_text.txt')2. 불러온 데이터의 review부분을 tokenize
자 이제 불러온 데이터를 tokenize해봅시다.
해당 review데이터는 보시면 알겠지만, 영어가 아닌 한국어 영화리뷰입니다. 따라서 konlpy를 사용하여 토큰화를 해볼겁니다.
위의 블로그에서도 똑같지만 konlpy의 다양한 모듈중에(Mecab, Twitter, kkma, komoran, okt) Okt모듈을 사용하여 tokenize를 해보겠습니다.
from konlpy.tag import Okt import json import os from pprint import pprint #밑의 tokenizing함수를 이해하기 편하도록 들어놓은 예시 #tokenizing함수의 반복문 구조를 보시면 아래에 나온 결과를 반복문으로 '/'를 구분자로 결합시킵니다. okt = Okt() okt.pos('당신을 보고 있으니 정말로 기분이 좋아집니다') # 하나의 문장을 토큰화 한 후 텍스트와 품사태깅을 / 구분자로 묶어준다. def tokenizing(docs): return ['/'.join(t) for t in okt.pos(docs,norm=True, stem=True)] train_pos = [] #훈련데이터 test_pos = [] #테스트 데이터 for row in train_df: try: train_pos0 = [tokenizing(row[1]),row[2]] #리스트 안에 한문장에 대해서 위에서 만든 tokenizing함수를 통해서 [[토큰화텍스트],긍/부정 여부]를 #리스트의 각문장별로 요소로 넣는다. train_pos.append(train_pos0) except: pass for row in test_df: try: test_pos0 = [tokenizing(row[1]),row[2]] test_pos.append(test_pos0) except: pass
위 코딩 결과 (훈련데이터의 첫번째 요소) 3. 데이터 전처리 및 데이터 탐색 - 1
이제 위에서 만든 데이터를 전처리 하고 어떻게 구조화 되어 있고 어떤 형식을 가지고 있는 녀석인지 확인해 보겠습니다.
#위에서 만든 데아터에서 긍/부정을 제외하고 token에 넣어준다. [[a],b] 에서 a만 넣는다고 생각하면 됨 tokens = [t for d in train_pos for t in d[0]] import nltk text = nltk.Text(tokens,name='NMSC')#nltk라이브러리를 통해서 텍스트 데이터 나열 len(set(text.tokens))#35425개의 고유 텍스트가 존재 text.vocab().most_common(10) #vocab().most_common(10) - 텍스트 빈도 상위 10개 보여주기 즉, count_values()를 통해서 내림차순한 것과 같습니다.자 그럼 위 코드를 통해서 만든 빈도 상위 50개 단어를 시각화 해보도록 하겠습니다.
import matplotlib.pyplot as plt from matplotlib import font_manager,rc %matplotlib inline font_fname = 'c:/windows/fonts/gulim.ttc' font_name = font_manager.FontProperties(fname=font_fname).get_name() rc('font', family=font_name) plt.figure(figsize=(20,10)) text.plot(50)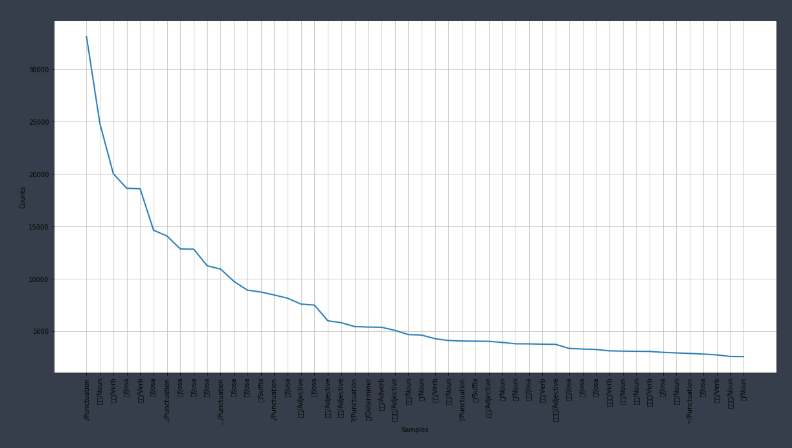
이처럼 시각화를 통해서 빈도가 잦은 단어들이 어떤것이 있는지 확인할 수 있습니다.
4.데이터 전처리 및 데이터 탐색 - 2
다음은 위의 문서 집합에서 단어 토큰을 생성하고 각 단어의 수를 세어 bag of words 인코딩한 벡터를 만드는 Countvectorization을 하겠습니다.
이를 하는 이유는 리뷰를 쓰는데 있어서 표현하고자 하는 단어는 한정적이며 빈도가 낮은 단어는 모델에 데이터로써 활용하면 정확도가 낮은 결과가 나올 수 있기 때문에 빈도가 높은 상위 10000개의 단어로 데이터를 정제하여 학습시키겠습니다.
그래서 리뷰 문장에서 해당 상위 10000개의 단어를 얼만큼 사용했는지를 데이터로 생성하여 그 각 countvectorizing한 데이터 즉, 리뷰 한개마다 긍정인지 부정인지를 나타내는 데이터를 만드는 것입니다.
만약, 위의 설명이 충분하게 전달되지 못했다면 아래의 코드에 주석처리한 것과 코딩한 것을 비교하면서 이해하시길 바랍니다.
#단어 빈도수가 높은 10000개의 단어만 사용하여 각 리뷰 문장마다의 평가지표로 삼는다. selected_words = [f[0] for f in text.vocab().most_common(10000)] #term_frequency()함수는 위에서 만든 selected_words의 갯수에 따라서 각 리뷰와 매칭하여 상위 텍스트가 #각 리뷰에 얼만큼 표현되는지 빈도를 만들기 위한 함수 def term_frequency(doc): return [doc.count(word) for word in selected_words] train_x = [term_frequency(d) for d, _ in train_pos] #train_x만 설명하자면 위의 결과로 도출되는 train_x의 구조는 아래와 같다 #[[1번째리뷰를 상위 10000개와 각각 매칭하여 각 10000개의 단어가 해당 문장에 얼마나 포함되는지를 확인]] #리스트 차원으로 표현하면 [[10000개],[10000개],[10000개]....[10000개]] 가장 바깥 리스트의 갯수는 기존 train_pos의 리뷰 갯수와 같다. test_x = [term_frequency(d) for d, _ in test_pos] train_y = [c for _, c in train_pos] #train_pos데이터에서 각 리뷰별 긍/부정 여부 데이터이므로 train_pos의 리뷰갯수와 같은 사이즈이다. test_y = [c for _, c in test_pos]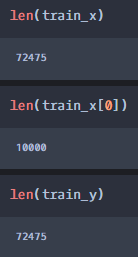
만든 데이터의 size #모델링을 하기 위해 리스트로 되어 있는 데이터 형식을 array로 바꿔주고 dtype도 실수로 바꿔준다. import numpy as np x_train = np.asarray(train_x).astype('float32') x_test = np.asarray(test_x).astype('float32') y_train = np.asarray(train_y).astype('float32') y_test = np.asarray(test_y).astype('float32')5. 감정분석 모델링
그럼 만든 데이터를 이용하여 모델에 학습시켜볼까요?
모델은 tensorflow, keras를 활용하여 text를 학습시킨 후 긍/부정을 예측하는 알고리즘을 만들었습니다.
모델의 dense를 쌓을 때 아래와 같은 방법으로 층을 쌓았습니다.
1. 맨 상단의 두 개 dense층은 64개의 유닛을 가지고 relu활성화함수사용
2. 마지막 층은 1개의 유닛으로 시그모이드 활성화함수를 사용하여 - 즉 긍정의 리뷰일 확률을 출력한다. (부정의 리뷰일 확률은 어떻게 추출하지?)3. 손실함수로 binary_crossentropy사용 / rmsprop 옵티마이저를 통해서 경사하강법 진행
백문이불여일견이라는 말처럼 바로 코딩한 내용으로 확인해보겠습니다.
from keras import models from keras import layers from keras import optimizers from keras import losses from keras import metrics #tensorflow.keras를 활용하여 모델의 층 입력하기 model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))#10000개를 추출했으므로 shape는10000 model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1, activation='sigmoid')) #모델 생성 model.compile(optimizer=optimizers.RMSprop(lr=0.001), loss=losses.binary_crossentropy, metrics=[metrics.binary_accuracy]) #모델 학습 model.fit(x_train, y_train, epochs=10, batch_size=512) results = model.evaluate(x_test, y_test) #예측 결과 results #83%의 정확도를 가진다.6. 완전히 새로운 데이터로 결과 예측하기
그럼 83%의 정확도를 나타내는 모델을 이용하여 새로운 데이터를 입력받았을 때 어떤 결과를 도출해주는지, 또한 그에 대한 정확도는 얼마나 되는지 확인해보도록 하겠습니다.
def predict_pos_text(text): token = tokenizing(text) #okt.pos로 토큰화한 단어를 정리 tf =term_frequency(token)#토큰화된 단어를 이용해서 가장 많이 등장하는 단어와의 빈도수 체크 data = np.expand_dims(np.asarray(tf).astype('float32'), axis=0) #data는 그럼 입력받는 text가 한 문장만 받기 때문에 가장 바깥 리스트의 요소 갯수는 1이 될 것이고 #마찬가지로 리스트 안 리스트 요소내의 갯수는 10000개가 될 것이다. #np.expand_dims?? score = float(model.predict(data)) #새로운 데이터를 받으면 결과 예측 if(score > 0.5): print("[{}]는 {:.2f}% 확률로 긍정 리뷰입니다.\n".format(text, score * 100)) else: print("[{}]는 {:.2f}% 확률로 부정 리뷰입니다.\n".format(text, (1 - score) * 100))새로운 데이터 입력에 따른 모델의 예측 결과
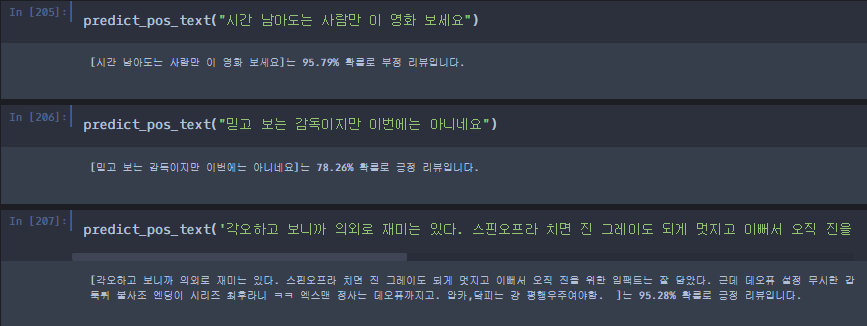
위의 결과와 같이 비교적 정확하고 수준 높은 결과를 보여주는 것을 알 수 있습니다.
아직은 딥러닝에 대한 학습이 부족하고 앞으로도 계속 공부를 해야되기 때문에 모델을 튜닝하는 것에 대해서 더 깊은 공부가 필요합니다. 그래서 더 정확한 모델을 만들기 위해서 이에 관련하여 학습을 한 후 직접 dense층을 쌓아서 직접 모델을 만들어 볼 계획입니다.
바로 다음 포스팅은 실제 최근 영화의 네이버 평점 데이터를 수집하여 각 사람들이 평가한 별점과 평가한 내용을 모델에 넣어 예측한 결과와 비교하여 모델을 실제 분석에 접목할 수 있는지 타당성을 검증하고 분석해보는 시간을 갖도록 하겠습니다.
'ML, DL & Python > 감정분석' 카테고리의 다른 글
감정분석 모델을 이용한 네이버 평점 긍/부정 분석 (7) 2019.06.08