-
Train Test data distribution(Covariate Shift) - 2ML, DL & Python/Train Test Distribution 2020. 11. 29. 18:51
저번 포스팅에서 Train과 Test의 분포가 다른 것이 모델을 구축하거나 학습을 진행할 때 어떤 문제점이 있는지 알아보고, 분포가 다른 것을 어떻게 확인할 수 있는지 PCA, t-sne 분석 방법론을 통해서 확인해봤습니다.
이번 글에서는 두 클래스(Train, Test)의 분포가 다른 것을 ML로 간단한 모델을 구축하여 확인할 수 있는 방법과 분포가 다른 특정 input 변수들을 직접 도출하여 소거하는 과정을 거쳐서 분포도를 최적화하는 과정을 진행해보겠습니다.
1. Train, Test classification
이 방법론은 처음 접해보시는 분들도 많으실텐데요. 이해하면 다른 어떠한 비교들보다 굉장히 직관적인 파악 방법입니다.
말 그대로 input 데이터들로 Train과 Test를 분류하는 모델을 만드는 것입니다. Train을 1, Test를 0 아니면 반대로 설정해도 상관없습니다. 이렇게 데이터를 구축한 뒤 Train과 Test를 예측하는 분류기를 만듭니다.
그럼 분류한 뒤 어떻게 분포가 다른지 비교하나요?
이러한 의문을 가질수도 있는데요. 결국엔 우리가 수많은 분류 데이터를 접했을 때 타겟이 되는 라벨을 예측을 잘할수록 결과에 해당하는 라벨을 잘 나누는 변수를 잘 설정하거나, 만들었다는 의미가 됩니다. 그렇기 때문에 Train, Test를 예측했을 때 예측성능이 좋을수록 그 두 데이터를 잘 나누는 input 변수들이 존재한다는 것을 의미합니다. 따라서 우리는 acc, auc, f1-score...등의 결과값이 최대한 0.5 즉, 두 클래스를 잘 나누지 못하는 랜덤의 상태가 되도록 수렴하게끔 전처리를 진행해야 합니다.
그러면 classifier를 생성하여 모델을 만들어보겠습니다. 모델을 extraTree를 통해 간단하게 구현했습니다.
def test_prediction(data): """Try to classify train/test samples from total dataframe""" # Create a target which is 1 for training rows, 0 for test rows y = np.zeros(len(data)) y[train_idx] = 1 # Perform shuffled CV predictions of train/test label predictions = cross_val_predict( ExtraTreesClassifier(n_estimators=100, n_jobs=4), data, y, cv=StratifiedKFold( n_splits=10, shuffle=True, random_state=42 ) ) # Show the classification report print(classification_report(y, predictions)) # Run classification on total raw data test_prediction(total_df_all)
결과를 확인해보면 대부분의 metric가 높은 값을 가지며, 위의 시각화 결과들로 알 수 있듯이 두 클래스(학습셋,테스트셋)의 분포가 다르기 때문에 둘을 구분할 수 있는 input 데이터들이 존재한다는 것을 확인할 수 있습니다.
반대로 분포가 거의 같을 때의 eval metric이 어떻게 도출되는지를 확인해보겠습니다.
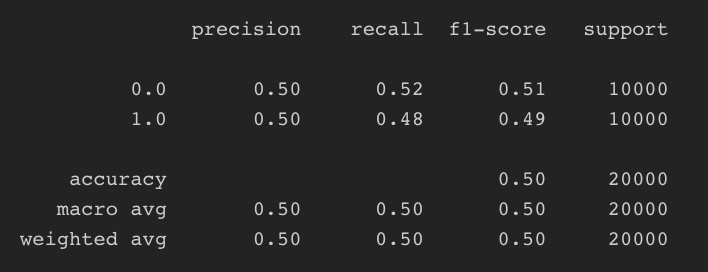
물론 제가 사용한 분포가 같은 데이터들은 정수형(5~9점 척도) 변수가 많은 데이터셋이였는데 이따가 시각화로 보여도 드리겠지만 그 분포가 거의 같기 때문에 모델도 어떻게 구분해야할지 모르는 상태인 0.5에 수렴하는 것을 알 수 있습니다.
위의 방법론들을 통해서 해당 Train, Test의 분포가 굉장히 다르고, 그 class(train, test)를 구분할 수 있는 input변수들이 존재한다는 것을 알게되었습니다. 그렇다면 어떤 특정 변수가 분포가 다르고 그것을 제거할 수 있는 방법론에 대해서 소개해드리겠습니다.
2. Feature by Feature distribution similarity
해당 방법론은 변수별로 유사도를 측정하여 그 유사도가 통계적으로 유의미한지 유의미하지 않는지를 비교하여 변수를 소거하는 방법론입니다. 이 때 유사도는 각 클래스별 변수들의 분포를 뜻하며 유사도를 측정하는 방법론으로는 p-value를 통해서 유의확률로 비교하겠습니다.
def get_diff_columns(train_df, test_df, show_plots=True, show_all=False, threshold=0.1): """Use KS to estimate columns where distributions differ a lot from each other""" # Find the columns where the distributions are very different diff_data = [] for col in tqdm(train_df.columns): statistic, pvalue = ks_2samp( train_df[col].values, test_df[col].values ) if pvalue <= 0.05 and np.abs(statistic) > threshold: diff_data.append({'feature': col, 'p': np.round(pvalue, 5), 'statistic': np.round(np.abs(statistic), 2)}) # Put the differences into a dataframe diff_df = pd.DataFrame(diff_data).sort_values(by='statistic', ascending=False) if show_plots: # Let us see the distributions of these columns to confirm they are indeed different n_cols = 7 if show_all: n_rows = int(len(diff_df) / 7) else: n_rows = 2 _, axes = plt.subplots(n_rows, n_cols, figsize=(20, 3*n_rows)) axes = [x for l in axes for x in l] # Create plots for i, (_, row) in enumerate(diff_df.iterrows()): if i >= len(axes): break extreme = np.max(np.abs(train_df[row.feature].tolist() + test_df[row.feature].tolist())) train_df.loc[:, row.feature].apply(np.log1p).hist( ax=axes[i], alpha=0.5, label='Train', density=True, bins=np.arange(-extreme, extreme, 0.25) ) test_df.loc[:, row.feature].apply(np.log1p).hist( ax=axes[i], alpha=0.5, label='Test', density=True, bins=np.arange(-extreme, extreme, 0.25) ) axes[i].set_title(f"Statistic = {row.statistic}, p = {row.p}") axes[i].set_xlabel(f'Log({row.feature})') axes[i].legend() plt.tight_layout() plt.show() return diff_df # Get the columns which differ a lot between test and train diff_df = get_diff_columns(total_df.iloc[train_idx], total_df.iloc[test_idx])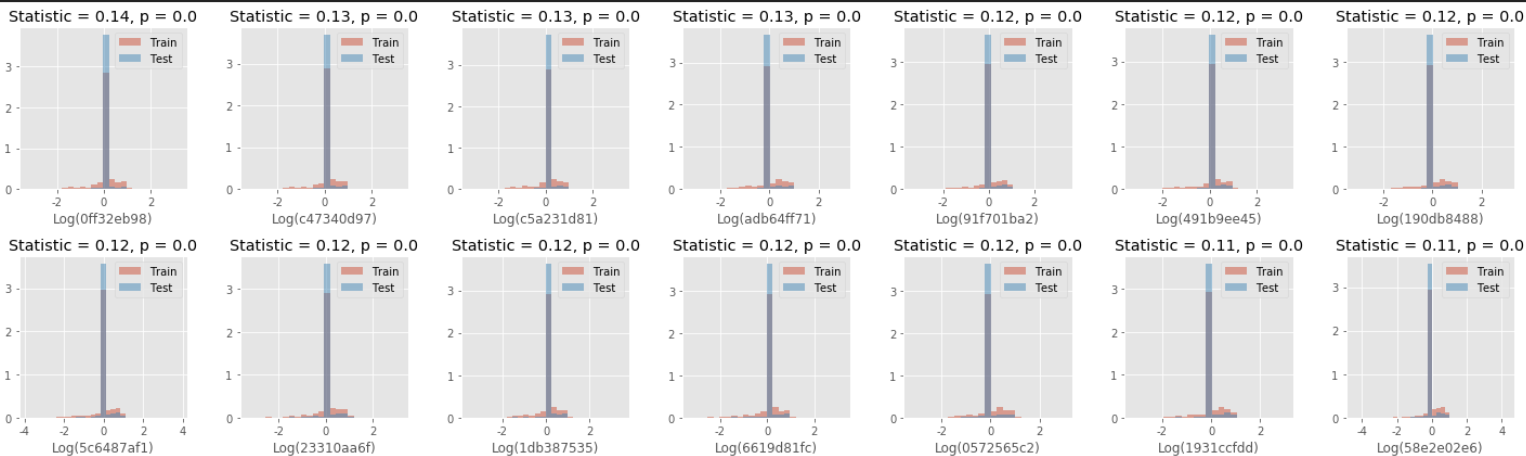
결과는 위와 같이 나오게됩니다. 각 변수별로 클래스별 유사도를 측정하고 통계값의 범위를 벗어나는 변수들만 추출하여 분포도를 그린 것인데 상당히 두 클래스의 분포가 다른 것을 확인할 수 있습니다.
반대로 두 클래스의 분포가 같은 데이터의 분포도를 확인해보겠습니다.

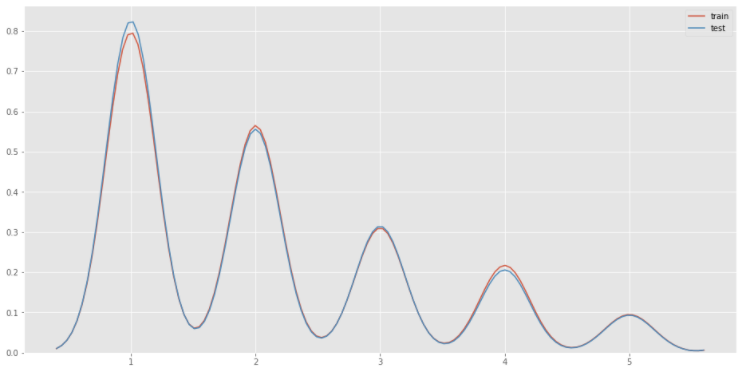
두 클래스의 분포가 거의(아예?) 같은 것을 볼 수 있습니다.
자 이제 어떤 변수들이 분포가 다른지 확인했으니 여기서는 변수소거를 통해서 다시 classifier 모델에 넣어보겠습니다.
소거하는 방법 이외에 이상치처리, normalization을 통해서 전처리할 수도 있습니다.
# 통계분석을(유의확률 비교) 통해 분포가 다르다고 도출되는 변수들을 제거했을 때 print(f">> Dropping {len(diff_df)} features based on KS tests") test_prediction( total_df.drop(diff_df.feature.values, axis=1) )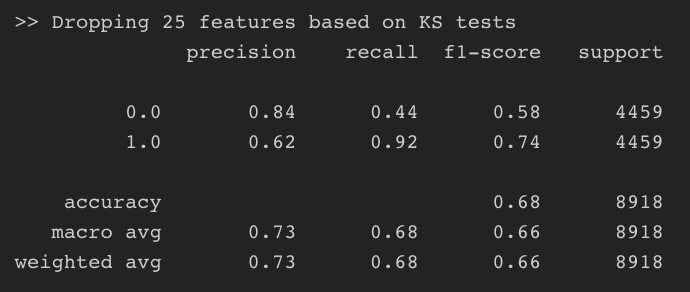
25개의 변수를 제거했으며 위의 결과와 비교했을 때 전반적인 평가지표들이 0.5에 수렴하고 있음을 알 수 있습니다. 하지만 아직도 두 클래스를 구분할 수 있는 분포가 다른 변수들이 존재하는 것을 확인할 수 있습니다.
3. feature decomposition
위에서 도출한 결과로 통계분석을 활용한 변수소거 방식으로 평가지표를 개선한 것을 확인할 수 있습니다. 하지만 여전히 분포가 다른 문제점이 존재하기 때문에 이 부분을 확실하게 해결할 수 있는 방안이 필요합니다.
따라서 위에서 분석한 pca, t-sne, svd방법론을 이용하여 차원축소를 진행하며 최대한 해당 데이터의 손실을 막으면서 데이터의 설명력을 보존할 수 있는 변수들만을 소거하여 분포도를 맞추는 방법론입니다.
COMPONENTS = 20 cm = plt.cm.get_cmap('RdYlBu') # List of decomposition methods to use methods = [ TruncatedSVD(n_components=COMPONENTS), PCA(n_components=COMPONENTS), FastICA(n_components=COMPONENTS), GaussianRandomProjection(n_components=COMPONENTS, eps=0.1), SparseRandomProjection(n_components=COMPONENTS, dense_output=True) ] # Run all the methods embeddings = [] for method in methods: name = method.__class__.__name__ embeddings.append( pd.DataFrame(method.fit_transform(total_df), columns=[f"{name}_{i}" for i in range(COMPONENTS)]) ) print(f">> Ran {name}") # Put all components into one dataframe components_df = pd.concat(embeddings, axis=1) # Prepare plot _, axes = plt.subplots(1, 3, figsize=(20, 5)) # Run t-SNE on components tsne_df = test_tsne( components_df, axes[0], title='t-SNE: with decomposition features' ) # Color by index sc = axes[1].scatter(tsne_df[:, 0], tsne_df[:, 1], alpha=0.2, c=range(len(tsne_df)), cmap=cm) cbar = fig.colorbar(sc, ax=axes[1]) cbar.set_label('Entry index') axes[1].set_title("t-SNE colored by index") axes[1].xaxis.set_major_formatter(NullFormatter()) axes[1].yaxis.set_major_formatter(NullFormatter()) # Color by target sc = axes[2].scatter(tsne_df[train_idx, 0], tsne_df[train_idx, 1], alpha=0.2, c=np.log1p(train_df.target), cmap=cm) cbar = fig.colorbar(sc, ax=axes[2]) cbar.set_label('Log1p(target)') axes[2].set_title("t-SNE colored by target") axes[2].xaxis.set_major_formatter(NullFormatter()) axes[2].yaxis.set_major_formatter(NullFormatter()) plt.axis('tight') plt.show()
제가 그리고 보니까 첫번째 시각화는 코로나 바이러스와 비슷한 모양이군요...
아무튼 변수들을 여러 축소방법론을 통해서 비교해본결과 처음에 비교한 결과보다 분포도 차이가 별로 안나는 것을 확인할 수 있습니다.
이를 기반으로 하여 소거할 변수로 리스트업된 데이터를 소거한 후 classifier로 분류해보겠습니다.
# Get the columns which differ a lot between test and train diff_df = get_diff_columns( components_df.iloc[train_idx], components_df.iloc[test_idx], threshold=0.1 ) # Run classification on total raw data print(f">> Dropping {len(diff_df)} features based on KS tests") test_prediction( components_df.drop(diff_df.feature.values, axis=1) )
최종 결과를 비교해보면 위의 차원축소 방법론들을 이용했을 때가 단순 통계분석으로 변수를 소거했을 때보다 변수의 distribution dissimilar문제를 대폭 개선한 것을 확인할 수 있습니다. 평가 지표를 확인해보면 거의 모든 eval metric이 0.5에 수렴해졌음을 알 수 있습니다.
4. 글을 마치며
지금까지 train과 test의 분포가 다름으로써 나올 수 있는 문제점과 분석시에 생길 수 있는 문제들에 대해서 살펴보고 분포가 다른 것을 확인할 수 있는 다양한 방법론, 해결할 수 있는 방법론에 대해서 살펴보았습니다.
물론 이전 포스팅 및 위의 방법론이 정답이 아닐 수 있지만 이와 같은 방법론을 통해서 학습셋과 테스트셋의 distribution dissimilar 문제를 개선할 수 있는 것을 확인할 수 있습니다.
방법은 더 다양하겠지만 이번 포스팅을 통해 train, test간의 분포 불균형 문제 해결을 해결하여 real world 데이터 상태 즉, 실제 적용될 문제에서도 학습시킨 모델이 overfitting없이 좋은 결과를 낼 수 있다는 것을 배울 수 있게 되엇습니다.
이 외에 또 다른 방법론을 알고 계신 분은 주저없이 공유해주시면 감사하겠습니다!!
*code
minyong-shin/blog-code-storage
블로그에서 분석한 코드를 정리한 저장소입니다. Contribute to minyong-shin/blog-code-storage development by creating an account on GitHub.
github.com
'ML, DL & Python > Train Test Distribution' 카테고리의 다른 글
Train Test data distribution(Covariate Shift) - 1 (5) 2020.11.29